
The artwork you see above was created using an AI art generator called Midjourney. I typed four words: religious and superstitious terror.
Don’t worry, I’m fine, I plucked that phrase out of a book I happened to be reading.
First, the generator gave me four thumbs. I chose which I wanted to enlarge. Obviously I picked the first one.

I’m also creeped out by that third one, with the elongated head and the tiny little person which I’m sure is a floating child monk ghost.

As a side note, I’m noticing a disproportionate number of human(like) figures with their backs turned. I wonder if the algorithm has been trained on large numbers of back views because it can’t yet do faces and limbs very well?) People (especially women) from behind was a familiar motif in 17th century Dutch painting (e.g. Vilhelm Hammershøi) and probably also in modern travel and stock photography, as humans provide human scale but a back view anonymises its subject and provides a first person point of view.
In the future, you won’t buy artists’ works; you’ll buy software that makes original pieces of “their” works, or that recreates their way of looking at things.
Brian Eno, Wired 3.05, May 1995, p. 150
All right, that’s it. I’m a convert. The first AI art generator I used was Wombo. I quickly moved on to Deep Dream Generator, and occasionally use NightCafe Studio. I wrote about that here. But I can’t be bothered with any of those now. While the news feed was filled up with other news in 2022, it was easy to miss the announcement that the beta of DALL-E 2 had been released. (Midjourney uses that, pretty much.)
If you’re waiting for an invitation to DALL-E 2, try NightCafe instead. As of 22 August 2022, they have launched STABLE DIFFUSION.
See my more recent posts:
With Stable Diffusion, NightCafe users will be able to generate a new level of incredible creations, with an all-new state-of-the-art algorithm on par with DALL-E 2 and Midjourney.
At NightCafe, your access to Stable Diffusion comes with our trademark unrivalled expression, tweaks and controls.
This is a gamechanger for AI generated art. This engine is NOT LIKE THE OTHERS. This one will… maybe… do exactly* what you tell it to? Midjourney is amazing.
*it doesn’t

HOW DOES IT WORK?
- Get yourself a Discord account if you don’t have one already. (This app is generally used for group chats, but Midjourney AI generation all happens within the app. It’s a bit weird, but it works.)
- Sign up for Midjourney here.
- Keep reading so you don’t waste your free 25 time credits. (I bet you’ll want to sign up after that.)
Because this thing is in beta, the algorithm is still learning, we are still learning it, and no documentation will tell you everything. Unfortunately, Discord is great for discussion and hopeless for archiving. This may be regrettable in future, unless someone’s creating an archive.

IS MIDJOURNEY EXPENSIVE?
At the moment you can get a plan for $USD10 per month.
FYI, I blew through it in two days of heavy use. I upgraded to Standard Plan after that. I had that last month. Spent 53 hours on it. (It tells you.) Ran out of fast hours but you can use it as much as you want on lazy setting. Still works pretty fast as far as I’m concerned, though I do wonder how much of that is to do with the fact I’m on Australian time, when most of the Northern Hemisphere is in bed. Decided to give Midjourney a rest this month to focus on doing other things like mowing the grass. But mainly, actually, last month Midjourney tried a few beta parameters which worked REALLY WELL and then deactivated them so they could work on them. I’m going back once those test parameters are back for good. But actually, the paddock weeds can do a Triffids for all I care. I’m testing out Stable Diffusion this month.
Some people are saying ten bucks costs too much. I’m not sure what they’re comparing it to? Not to commissioned digital artists. What you’re buying: some heavy-duty processing power.
Someone on the forum made this point:
I understand that it might feel a lot of money, but given what kind of hardware (no, you can’t run this on your local GPU even if you have a $2000 3090Ti extra nice) is required to do these large models and run all the processing at reasonable and even fast times … I am just so thankful to have access to it in a flatrate model. And sure … 5 years down the line newer server GPUs and other improvements will make the pricing of today feel expensive … but today it is extremely cheap and we get access to cutting edge technology without having to invest a ton of money.
GeraldT
However, the ethics behind charging to use the information run on those super computers is another matter entirely. Regarding DALL-E, David O’Reilly has this to say:
Using millions of investor dollars, Dall-E has harvested vast amounts of human creativity — which it did not pay for and does not own or credit — and demands investorship over whatever you make (find) with it.
Paying for it benefits a tech company on the back of a century of human effort — a bullshit deal.
Dall-E undermines the work of creators of all kinds, most obviously photographers, illustrators, and concept artists who shared their work online, and never asked to be included in a proprietary learning model. It rips off the past generation for the current one and charges them money for it. Scam.
Because it’s black box, passing off Dall-E images as one’s work is always going to be akin to plagiarism. All controls are hidden and many ordinary words are censored. Like Google it uses opaqueness to conceal ideology, very far from being ‘Open AI’.
@davidoreilly.2
Opinions vary. Make up your own mind, I guess. I’m a digital artist myself, and AI art is here to stay. Better the devil you know.
Although I blew through my monthly quota in two days, I got many usable images out of it. The success rate is very good. And I’m new to it. The learning curve is quick. In fact, you don’t need to know much at all if you don’t mind what kind of art Midjourney gives you.
However, if you want to art direct it, you’ll be making a lot of re-rolls. To get to that next level, you’ll be blowing through that 200 minute quota quickly, without much to show. So really, if you’re on the $10 plan, you sit in this awkward place where you’re pretty sure you could get something better if you gave it another couple of re-rolls, but you want to conserve your limit.

Honestly, this must be what gambling addiction feels like. “If I just re-roll one more time, it’ll give me the perfect piece of art!” Do what’s right for your psychology, I guess.
Once you have a paid account (including the basic plan), you’re expected to leave the newbie and general channels and generate art by DMing the Midjourney Bot. (If you stay on the Newbie channel the bot kicks you off, as I found out.)
I didn’t roll my account over but I’m hearing annoyance: Midjourney doesn’t send you an email or message telling you you’ve been charged for the following month. They just do it without telling you. It’s up to you to unsubscribe. This feels wrong when we’re all very used to our mobile phone companies and streaming services sending us emails to tell us our plans have been rolled over. So, if you subscribe to Midjourney and plan to try it for a limited time, set a reminder on your calendar.
In case you’re brand new to Discord, you’ll find your direct messages by clicking on the blue Discord icon at the top, left hand corner of the screen.
Chatting with the bot is great, because now you won’t have a feed filled up with other people’s “imagines”. (That’s what people call these artworks. I dunno if it’ll stick. Midjourney calls them “generations”.)

Bear in mind: Although it looks like you’re making stuff that’s entirely private between yourself and a bot, the artworks themselves are not private. They can be seen by others, and do not belong to the users who prompted them. (You can use them however you like. So can others.)

(Obviously I have done a lot to it! But instead of spending two days, I spent two hours.) The logos/signage were also made in Midjourney with prompts like ‘neon sign retro hamburger restaurant’ and ‘hamburger signage retro 1960s’.


A TIP FOR MAKING THE MOST OF YOUR TIME CREDIT
Legend has it that the thumbs (the 2×2 grid) use barely any processing power. Nonetheless, Midjourney snatches a disproportionate amount of your time credits to process them. What really uses their expensive computing power: Your upscales.
If you’re on a Standard Plan you have the option of switching to relax mode.
Hint: Switch to “relax” mode to generate the thumbs. Do this by typing /relax [ENTER] in the Discord server. Generate thumbs to your heart’s content.
When it’s time for upscaling, switch back to “fast” by typing /fast [ENTER] in the Discord server. This is because you have to be in /fast mode to access Upscale to Max.
If you don’t do this, you will burn through your fast time real quick. Then you’re stuck in relaxed for the rest of the month unless you pay extra for more “fast” processing time.
I’m not sure if this is because I’m on Australian time, generating art when most of the world is asleep, but I find the fast mode isn’t all that much faster than relax mode. Which is good. Midjourney’s relax mode is still faster than other AI generators I can think of.
HOW TO SPEND MORE: THE QUALITY PARAMETER
--q
What does that do? –q 2 means Midjourney will spend twice as long on your image. –q 3 means Midjourney will spend triple as long making your image. (It did go up to 5, but that has been temporarily disabled.)
Does increasing the –q make a better image? Sometimes.
First, here’s my “Flood of Baked Beans” ‘photo’ made without increasing the --q.
/imagine [ENTER] raining baked beans :: 2 flood of baked beans, cityscape, cinematic view, cinematic lighting, storm, establishing shot –ar 3:2
Here it is again. The only thing I changed was adding doubling the time spent on it with --q 2.
raining baked beans :: 2 flood of baked beans, cityscape, cinematic view, cinematic lighting, storm, establishing shot –ar 3:2 –q 2
If you’re wondering already about the meaning of :: 2, that means I want Midjourney to pay particular attention to baked beans. Like, double the amount of attention. (Looks like it listened, too.)
Obviously, it’s impossible to do a controlled experiment because Midjourney is re-rolling the dice and you don’t get the same image twice anyway. But because the first one was such high quality, I don’t see any difference after spending double the time on it.

WHERE DOES MIDJOURNEY FIT IN THE AI ART GENERATION LANDSCAPE?
If you’re interested in where AI art is at right now and the current state of Midjourney, its relationship to DALL-E, why it’s called DALL-E and how fast all this is changing, this video will explain all that. (It’s changing very quickly!)

DALLE is great at creating more accurate, clear images. But Midjourney makes the BEST album covers. It feels like DALL-E was trained on stock photography, while Midjourney was trained on concept art & renaissance paintings.
@Johnny Motion
RESOURCES AND SOFTWARE TO USE ALONGSIDE MIDJOURNEY
USER MANUALS
- If you’re the sort of person who reads instructions, Midjourney has a QuickStart Guide.
THE COMMUNITY FEED WITHIN MIDJOURNEY
Once you subscribe (even on the lowest tier) you get access to community images. What I didn’t realise until I subscribed, and how useful this would be: You can copy and paste other people’s prompts. You’ll learn so much simply by doing this. Find other people’s prompts by going to Community Feed on your own Midjourney profile page. You can bookmark the ones you love, copy their prompts.
PHOTO SOFTWARE
I use Affinity Photo because it has one upfront price and does everything I need. Don’t get Adobe Photoshop unless you need features Affinity Photo doesn’t have, or unless you already own a huge library of presets, plug-ins and brushes (which won’t work in Affinity Photo). Even if you never learn much features of your photo software, a few tools will make AI art look way better, namely: The inpainting tool (paint over, automatically remove or fix) and the clone tool. The OpenSource version is, of course, good old GIMP.
Speaking of GIMP, it’s ugly and a bit janky. Meet PhotoGimp, a project that makes GIMP a whole lot more like Photoshop, not by charging you a monthly fee, but by making GIMP look and act more like Photoshop.
Photopea is free advanced photo software, used and loved by many.
PHOTOBASHING
Photobashing: Photobashing is a technique that consists of using multiple digital assets like pictures, textures, and 3D models to create realistic-looking artwork.
One technique: Use Midjourney to make a background (it can be great at backgrounds) and create your humans/creatures elsewhere. Remove background and then paste it all together in your photo software.
One way to get photorealistic humans with fully-customisable facial expressions, characteristics and bodies: Sign up for the brand new beta of Metahuman, software developed by Unreal Engine. If you go to the Unreal Engine website, you can find the Metahuman sign up under products. You can create the human you want then take a screenshot and remove the background.









You can remove backgrounds online at removebg.
ERASE AND REPLACE
You’ll find a whole suite of useful magic tools here, but of interest to Midjourney users: Erase and Replace. (Or inpainting, as it’s called in Stable Diffusion forks.) Say you’ve got this beautiful picture with one thing wrong: There’s an eyeball where the head should be.
Upload an image, paint over the part you don’t want, tell it what you do want and voila. It works better than I expected. But also kept telling me I was breaking their terms of service, even though I was only wanting an old man sitting in an armchair.


Your own way of enlarging images
Midjourney can do this but it costs you unnecessary time credit. The OpenSource way: Real-ESRGAN Inference Demo. People also recommend Cupscale. A paid, prettier way: Buy a copy of Topaz GigaPixel. (Update 16 August 2022: Topaz released all-in-one software combining their upscale, sharpen and denoise tools. There will be a discount for the first little while after release.) I paid for Topaz products a year ago and they put out (annoyingly) regular updates for a year. Then you have to buy it again to continue getting updates. (I’m still happy using last year’s software.)
Scott Detweiler is a good person to follow in this space. In this YouTube video he talks about a way to upscale your Midjourney images to gigantic sizes (for printing and professional art) using a free tool called ChaiNNer and it’s open source. Older Macs will have trouble with it.
There’s also SuperRes Diffusion, ClipDrop ($5/month), or SwinIR.
PROMPT INSPIRATION
These top two are new as of end of October 2022:
A very valuable free resource: Stable Diffusion Artist Style Guide. Includes tags for styles, a pop-out sidebar showing example of artist work and a star-rating to show how well Stable Diffusion recognises the artist. Obviously this is not made for Midjourney but this method of finding artists is great.
This modifiers guide for AI art lets you search for modifiers from a dropdown menu. Sort by angles, artists, effects, photo styles, technology and so on.
A huge list of Prompt Inspiration on Reddit (not just for Midjourney but for AI art generators in general)
Don’t forget good old Google Arts and Culture.
This Aesthetics Wiki can help you find prompts to make a particular style e.g. the entry for Honeycore: “Honeycore is centered around the rural production and consumption of goods such as honey, bread, and waffles. It is similar to Cottagecore in that rural agricultural imagery and values are emphasized, but the visuals are streamlined to create a colour palette of mostly pale yellows and browns…”
A Guide To Writing Prompts For Text-To-Image AI
Midjourney Styles and Keywords Reference, an extensive guide on GitHub with lists of theme and design styles, artists, material properties, intangibles and things you haven’t even thought of. WITH IMAGE REFERENCES. When you see people using words like ‘supersonic’, they’re probably read this document, or borrowed prompts from someone who has.
You can find all sorts of random generators on the web. One that makes me laugh: The Arty Bollocks Generator, which pumps out artist statements to go with pieces of art. This was made long before Midjourney, so it would be interesting to see what AI does with it.
My work explores the relationship between the body and UFO sightings. With influences as diverse as Rousseau and Roy Lichtenstein, new combinations are manufactured from both mundane and transcendent layers
Arty Bollocks Generator


Here’s another Prompter. Save the spreadsheet to your own Google drive. The guy who made Prompter also made his own QuickStart Guide which you may prefer over Midjourney’s own documentation.
SOCIAL MEDIA
Search the #midjourney tags on Instagram and Twitter, of course.
A Facebook group which is a spin off of “Procedural / Generative / Tech Art” group, but dedicated to AI generated images.



NOW TO THE PROMPT ENGINEERING
“Prompt engineering” is catching on in acknowledgement that using Midjourney to direct output is a skill in its own right.
If Midjourney has no idea what you want, probably because you’re using really obscure, highly metaphorical words, it’ll give you a pretty landscape instead.
Midjourney does not yet take specific art direction. However, at this rate it will in 5-10 years’ time. For an example of where this could go, there’s a Prompt Clips thread under the Prompt Craft chat on the Discord server for a growing number of examples where users post “groups of multiple words that reliably/consistently create a known effect on MJ output.” tl;dr: Midjourney is reliable if you can work out what to tell it.
There tends to usually only be one generation in a grid that’s close to the “literal” interpretation of any prompt. Now and then you get a grid and all four images are usable. Oftentimes, the excellent art you see on the Community Feed have been “re-rolled” many times (meaning numerous times hitting V and U.)
GENERAL HINTS FROM THE DISCORD CHAT WHICH MAY OR MAY NOT WORK FOR YOU
- Try using things like “
humanoid robot, metal spider” to get more arms. The basic idea is to try get MJ to blend two “big” ideas that have the details you want, rather than going for the details directly. tronseems to be a high impact word,- When making hybrids, a phrase such as “
cat bird hybrid” will confuse Midjourney. Try instead:cat-birdorcat :: bird. - Midjourney is bad at snakes. If you want a snake head try the term
basilisk. - You can’t tell it how many legs to give something but try
bipedalandquadrupedal. Gingeremphasises hairstyles (not the root vegetable)--no makeupemphasises faces--hdcan do weird stuff, it’s made just for landscapes. (It’s a parameter which gives you an image you can use as a desktop image.)- Try “
detailed diorama“. Dioramas can have really good spatial coherence if you find the right prompt. - 85% of the time, you do not want to enhance.
--stop 70is worth trying. See if you like it. - adding
--no backgroundmostly returns flat/gradient colour background, handy for importing into other image software.

HOW DO I MAKE MIDJOURNEY ARTWORK USING MY OWN IMAGE?
Midjourney lets you provide an image URL in the beginning of your prompt as a seed image.
If you’re familiar with, say, Deep Dream Generator, understand Midjourney does not work like that. With Deep Dream Generator, you upload a “base image”, then you choose/upload a “style image”. The algorithm will paste a story onto the base image you, personally provide. Midjourney will not be using your “base” (seed) image directly. Instead, it uses your url to check the image, then it goes back to its own massive database, sees what else it has like it, and uses that.
In any case, if you have an image you’d like to use as base, it needs a place to live on the Internet. It needs a url.
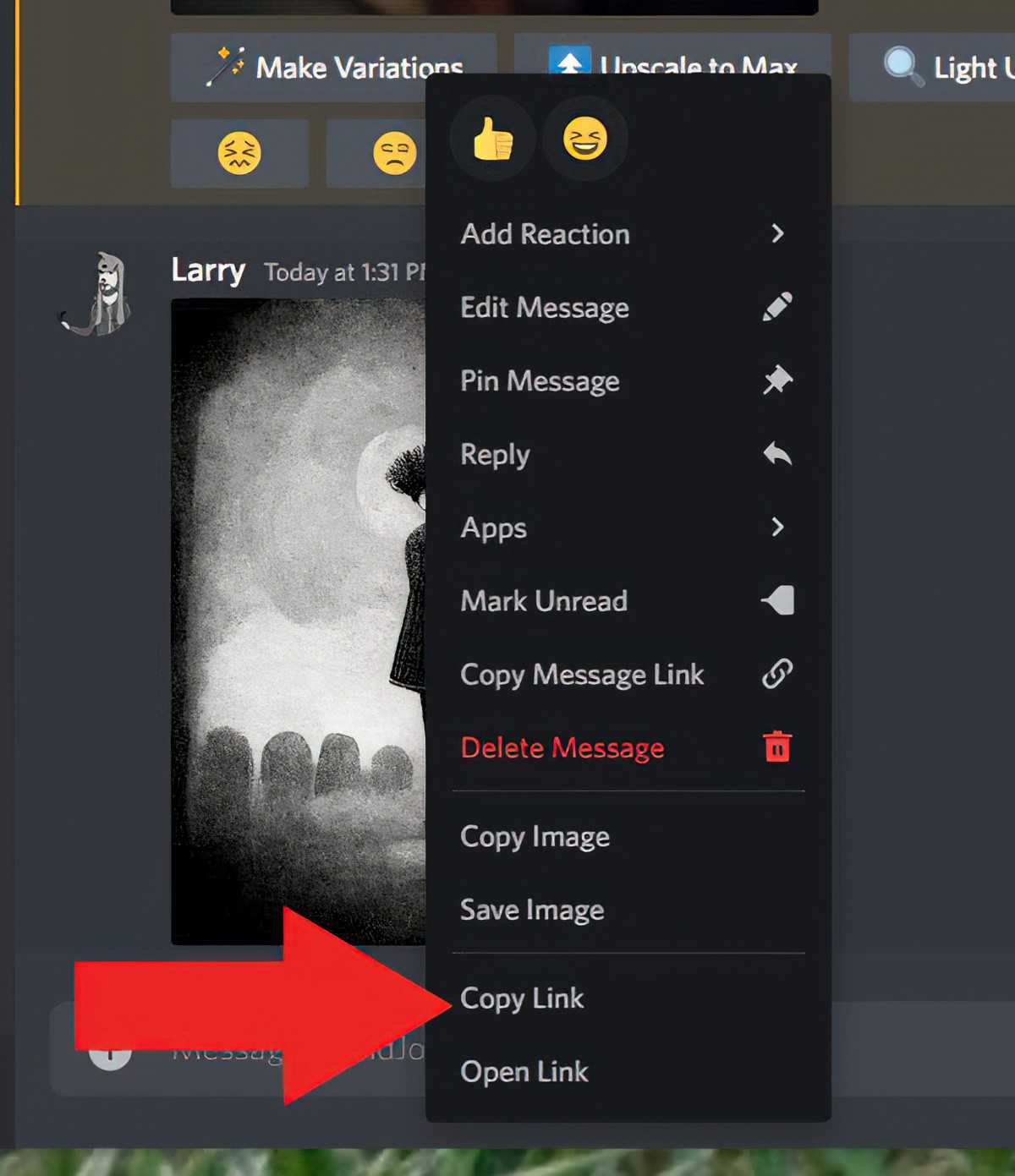
Simplest way: When you’re chatting to the Midjourney bot, drag an image into a new message. Hit enter. The image will upload. Right click on it. ‘Copy link’. Use that url at the beginning of your next /imagine. (You don’t need to do anything else, code wise. Just drop it in and write the rest of your prompt.)
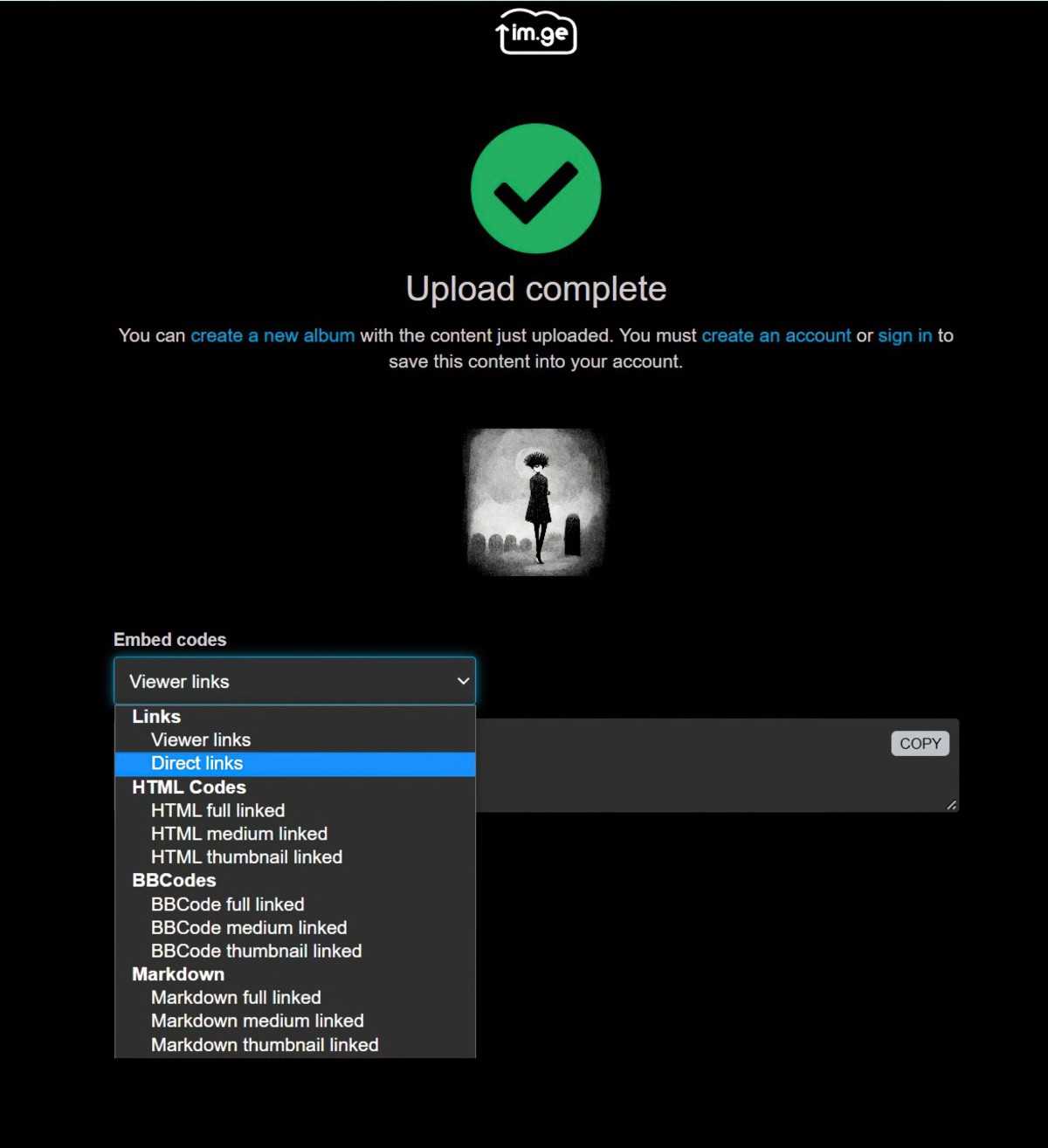
If you’d rather not keep images on Discord, you can upload images to: im.ge There’s a 50MB limit. You don’t need to create an account to get a temporary link, but if you make an account, you can keep your images there, organised in folders. There’s a slight trick to getting a link which ends in .jpg or .png (what Midjourney requires.) It offers a ‘viewer link’ by default, but you need the ‘direct link’.
TIPS FOR WORKING WITH MIDJOURNEY IMAGE LINKS
Double up. If you’re using both an image and a text prompt, describe in words what you see in the image. This seems to work better.
For best results, create a prompt image 512×512 in your photo software first and use that. (We are told values above 512 are unstable and may cause errors.)
TIPS FOR MIDJOURNEY PORTRAITS AND HEADSHOTS
Update beginning of September 2022: Midjourney is getting much better very quickly. The team roll out tests you can do using temporary parameters. I made the following real life versions of Ernie and Bert making use of a temporary --testp parameter in which they were testing out photorealism with a different, experimental algorithm. I love Midjourney’s vision of middle-aged Ernie and Bert from Sesame Street. I only wish I could buy Ernie’s shirt:


Don’t get me wrong, it also made some creepy stuff. I’ll spare you the Marge Simpson but have an Edgar Allan Poe. Remember, this image of Edgar Allan Poe doesn’t exist anywhere. It is made from existing photos of the guy:

I asked for an AI generated portrait of Katherine Mansfield, who died in 1923 at the age of 34 and… it gave me a portrait of Katherine Mansfield in her seventies.




If you want to create portraits, I recommend Betcha She Sews for an excellent how-to guide.
You’ll notice a lot of ageism and racism when creating portraits. It’s very difficult to create a middle-aged woman, for instance. Requests for people default to white, with the exception of anime and manga styles. “Woman” defaults to young. “Elderly woman” works, if you want a woman in her eighties. If you want a woman in her forties, your best bet is to prompt with “elderly” then stop it at 80% or something. If you want a full-body render, try prompts ‘full shot’ or ‘full body’. ‘Standing’ will also likely get you some legs.
There’s a strong white skin bias. Even “Black skin” and “dark skin” don’t work. Better instead to specify a location (city or country) or continent e.g. “in africa“, “african-american female“. Or find an actor with the skin you want and use their name as a prompt.
People (especially women?) get long necks a lot of the time. Try --no long neck. Also try making your image dimensions less tall.
Let’s go one further: --no long neck and double face whenever you’re making portraits. (See below for how to make a shortcut of this.)
If you try rerolling faces, faces only get worse, not better. At least, that’s what I’m finding. Your first face is going to be your best one.
Most results are artistic and stylized. But certain types of subjects (e.g. famous people) tend to push things more in a non-realistic direction.
If you’re getting a lot of distortion (e.g. in a face) try stopping an upscale at 50% (by typing --stop 50) then upscale again from there.
Use FaceApp not just on your own selfies — you can use it to fix AI generated faces as well.
Many people have tried to art direct angles (including me) to no avail. Midjourney returns front-on shots. Every now and then you’ll get someone looking to the side, but no prompt encourages various common portrait photography poses e.g. the 45-degree angle rule.

I tried every photography term I could think of. Every English phrase:
- 45 degree angle
- 3/4 angle
- looking off to the side
- side-on view
- etc
I even uploaded a 3D model with a 45-degree angle to use as an image prompt.
Nothing did anything to change the angle. That prompt image did change the aliens to look more human. But then I upped the --iw and got face on versions of the reference image.


In the end I dispensed with the prompt image and got a bunch of aliens, all staring straight at me.

But I knew it was possible, because I got one measly alien with a 45-degree head pose. I got it entirely be accident. (Also got an extra eye.)

Finally, I found a semi-reliable way to change the angle of a face in portrait. --in profile
This result isn’t great

But I only needed it for the face of my candy corn, who is going trick or treating.

EXAMPLES OF PORTRAIT PROMPTS FROM THE COMMUNITY FEED
All of these produced excellent portraits. Some are detailed, others not.
/imagine [ENTER] redhead girl in black dress in beautiful castle, black pearls and golden gems, glowing eyes, light freckles, portrait, biomech, conceptart, medium shot, unreal, octane, symmetrical, photorealism–ar 2:3 (Note that at this aspect ratio, the neck was really long.)/imagine [ENTER]Anime picture, long blonde hair, girl/imagine [ENTER]a beautiful sleepy punk sit at a window, wearing crop top and torn short pants, pretty face, Glamor Shot, Magnification, 8K, Lonely, Accent Lighting, De-Noise, symmetrical face, hyper-realistic --ar 13:16/imagine [ENTER]beautiful blonde lady in flower dress, hyperrealistic, ultra detailed, octane render, symmetric, 3d, majestic, dark fantasy, intricate, --q 2 --ar 24:36/imagine [ENTER] asian goth in shinjuku, dark dress, cyberpunk, fashion, biomech, red and turquoise lights, black-red-turquoise-lips, conceptart, highlights, symmetrical, portrait, pretty face, octane, unreal, realism --ar 2:3/imagine [ENTER]samurai skeleton skull cyberpunk klimt black red portrait 4k/imagine [ENTER]rotten tree spirit dryad with a beautiful face and flaming mouth and eyes + mushrooms + fungi + lichen + sketch lines + graphite texture + old parchment + guillermo del toro concept art + justin gerard monsters, intricate ink illustration --ar 9:16/imagine [ENTER]Glitchy Anime girl stands in a field of sunflowers, chromatic abberation, glitch art --ar 9:16 --q 2/imagine [ENTER]Gandalf the Mona Lisa --ar 9:16 --uplight/imagine [ENTER]gorgeous steampunk woman wearing hip hop clothes and sunglasses/imagine [ENTER]cyberpunk monkey/imagine [ENTER]hyperrealism, 3D, terrifying massive gate keeper of the underworld, character, Being, mystic, ultra realistic + octane render + 8k details + photography + cinematic + photorealistic + detailed textures + unreal engine + defocus
TOO MANY LONG NECKS?
Ridiculously long necks are a feature of Midjourney portraits.
Once you’ve learned the basics of Midjourney, head over to “How To Make Midjourney Your Bitch“. This Medium article explains how to change the Midjourney settings inside Discord to permanently avoid certain things e.g. --no long neck, double faces.
Obviously you can set up shortcuts for all sorts of things e.g. your favourite aspect ratios.
EARS
Midjourney *currently* does a terrible job with ears and hands. Get good at painting those in yourself, or wait for AI to evolve. Or you can look up ears of bald men online and cut them out for future reference. (Everyone else has hair in front of their ears.)
Adjust the saturation and vibrancy to match your own image. Oftentimes it looks better to blur the ears a little, too, pulling focus on the face.
EYES
Eyes are generally a little off. Oftentimes, pupils will be out of alignment, maybe only by a few pixels. But because humans are so focused on eyes, a tiny adjustment by hand makes all the difference.
eyewear
Midjourney infamously messes up horses, dogs, tables… It doesn’t always do a great job with glasses, either.
If you’re after a camera-facing headshot, instead of adding glasses in Midjourney, try one of the online glasses stores that lets you do a virtual try-on using a photo. Vint & York is a good one.
FULL BODIES
How long did it take to get a full-body alien, without any body parts cut off? When I used the prompt alien --ar 2:3 on its own, I got four head and shoulders shots. Next I tried full-body alien --ar 2:3 which gave me one head and shoulders shot, and three down to the knees. After a re-roll I got two out of four.

Next I tried full-body alien, bipedal. I got one full-body alien out of four.

‘Bipedal’ is fine and dandy if you’re making fantasy creatures, but what if I want a bog-standard human? Let’s try an elderly man. You wouldn’t want this face, but it took three re-rolls to get four full-body shots of elderly men.
I think when creating a man, bipedal is messing me up. I’ll save you the results.
/imagine [ENTER] elderly man, full-body –ar 2:3
In the case of a human bipedal must have thought I wanted something interesting going on with the legs (which would explain the old guy who skipped leg day above).
These four images are a good example of how Midjourney works. It doesn’t know if I want him facing towards me or away. Do I really want the whole body? How about Grandpa Midjourney here, who has cropped up twice? And do I really want a man? Or an elderly woman with a pretty scarf? The first roll frequently gives you one image you can work with. Sometimes none, sometimes two. Occasionally all four.
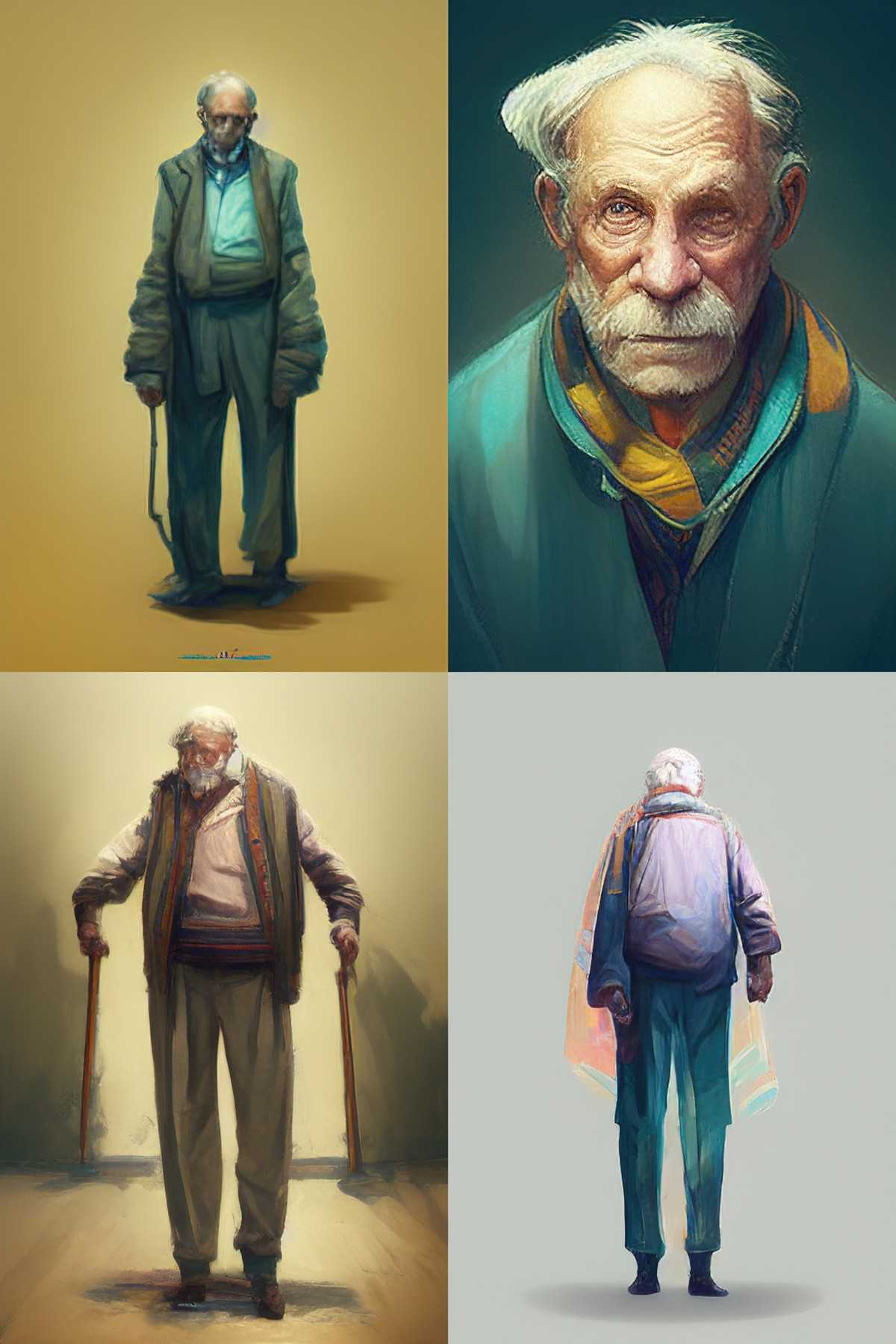
Hint: I’m finding ‘lonely’ is good as a prompt if you’re after a scene with one person in it.

If you want a full body of a woman, say, and you’re using prompts when tend to describe faces e.g. red hair, and also ‘beautiful’, then the algorithm thinks you want a portrait of a face. If you want a long shot of a woman, better to type ‘woman’.
A NOTE ON PUNCTUATION
At time of writing, it’s not yet clear where you should use commas, full-stops and colons in your prompts.
It’s not case sensitive.
Some users think punctuation does nothing. The developers have pointed out that people are misusing colons. Colons between all the parts of a prompt isn’t how they were meant to be used. The double colon is supposed to be used to guide the algorithm regarding weight. e.g. you want an image of a hamburger with a restaurant background but you keep getting not enough hamburger, too much background, in which case you type hamburger :: 2 restaurant :: 0.5 (I made that example up).
Here’s another view, from users @fractl and clarinet:
So
::is the only ‘official’ break in a prompt, but comma, plus, pipes all have some (minor) effects as well. Nothing consistent, but in some cases one may be better than another.Here’s a test I ran a while back:
Red pandaclearly shows the animal of that name.Red, pandaseparates them a little bit (a red-haired red panda)Red:: pandagives a panda that is redRed:: panda:: —no red pandais even more clearly a panda which is red (and not a red panda)
One thing is clear: You’re not writing an essay, so don’t use commas grammatically. Use commas to separate parts of an image, not, say, to list attributive adjectives in front of a noun.
Some people are making use of full stops. I’ve seen: gigantic robot monster. Eating a schoolbus. Octane render. Rainy. Realistic
Current wisdom: Commas are soft breaks, :: are hard breaks.
Note: the parameter of a prompt begins with two en dashes. THIS DOES NOT MEAN AN EM DASH. Sometimes software automatically corrects two en dashes to a single em dash, but the em dash is not recognised by Midjourney.
This: --ar 9:16
Not this: —ar 9:16 (This won’t work.)
Midjourney seems strangely forgiving of typos. Still, spell check your prompt before wasting your credit.
I’m also seeing the Boolean operator + in some of the top trending art. Stuff like:
scary cyberpunk ganguro mech-robot wearing hoodie + yellow honey oozing from body + cool street style + relaxed pose + centre image + Studio Ghibli style + moebius style + pastel color style + line drawing
Perhaps the plus symbol works like old-timey search engines, meaning if it comes after the plus, the algorithm will definitely factor it in? (In case you’ve never heard of Boolean logic, a plus sign means AND.) More likely, it’s a way for the user to keep track of grouping and ordering. (People use square brackets in the same way. It doesn’t mean anything to Midjourney.)
Looking through the Community Feed, I don’t think the algorithm pays any attention to spaces after commas. The spaces seem useful for our own reading ease. The exception is, don’t insert a space after the double dash of an argument.
Anyway, I had to check what that prompt gives us (it’s a modification on someone else’s):

EVOLVING YOUR CREATION: APPROACHES TO THE UPSCALING AND VARIATIONS BUTTONS
Midjourney gives you two rows of buttons: V for ‘create four new variations’ and U for ‘upscale’. Using this algorithm reminds me of going for a vision test. You tell the optometrist which looks more clear, gradually improving your vision.
But which button should you press first, to avoid wasting time credits?
- Upscale the generations you like after the first prompt then make variations of the upscales you like most.
- Keep picking variations until you get one you want to upscale.
- Upscale each image before hitting the V button. (Is this method the best way of achieving detail? Could be.)
Before you make variations, consider doing an upscale first. That extra bit of visualization effort can sometimes get you where you want quicker than just making additional random variations.
Betcha She Sews
IMAGINE, REROLL, VARIATION AND UPSCALE
/imagine renders a grid of possible compositions from your prompt inside a cached session
Reroll 🔄 also renders a grid of possible compositions from your prompt… plus adds another iteration of detail
Variation [V1] renders a grid similar to your selection… plus adds another iteration of detail
Upscale [U1] increases the size of your selection from thumbnail to full …plus adds another iteration of detail
AFTER THE EVOLUTION
--uplight at the end of your prompt uses a light touch to simplify details when it is rolled, and--stop 90 halts the whole render process like a handbrake at whatever percentage you specify (replace 90 with your own number)
WHAT IS SAMESEED?
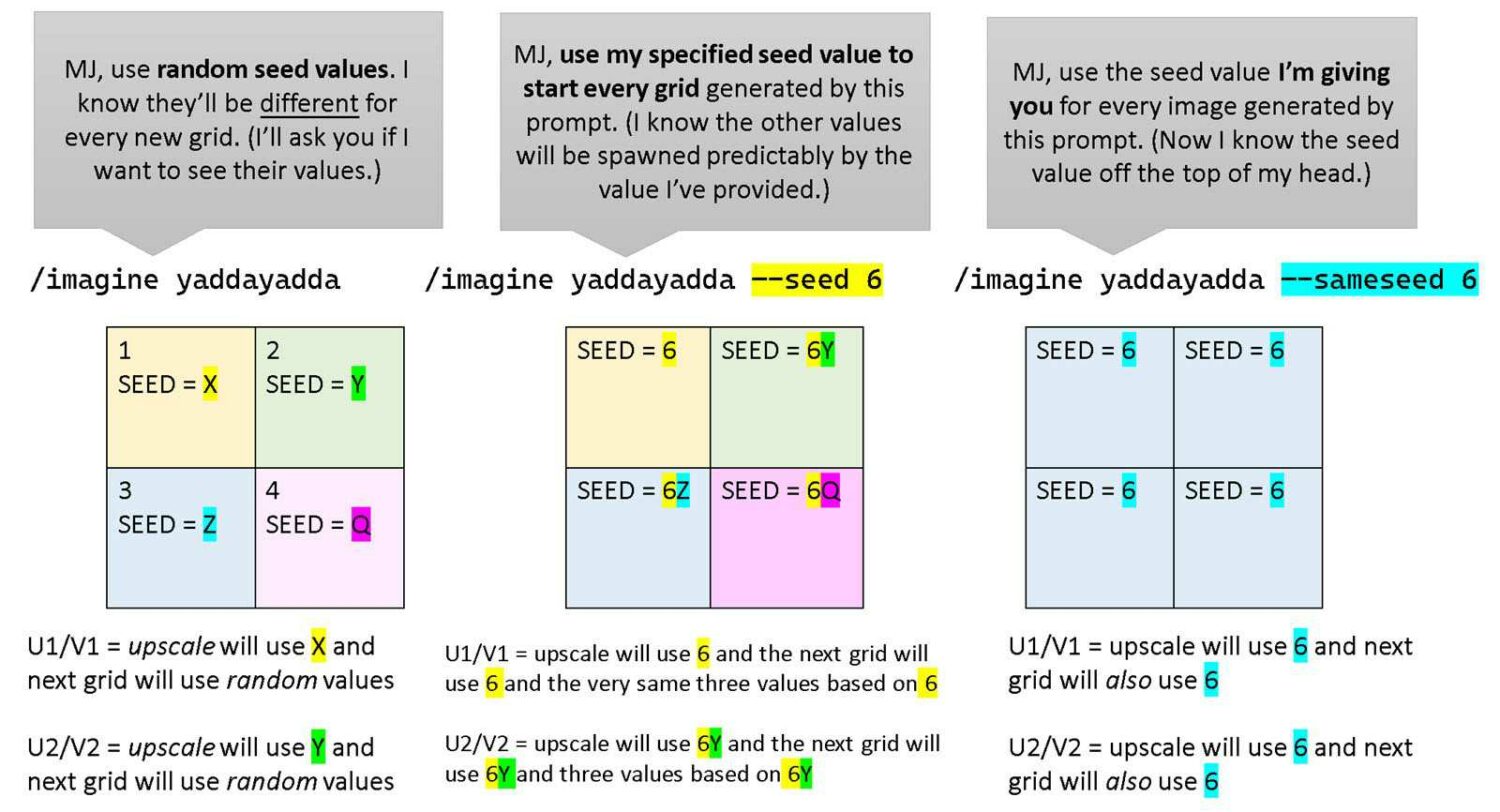
MESSING AROUND WITH WEIGHTS
--iw stands for image weight. Image weight refers to the weight of the uploaded image prompt versus the text portions of your command. Typing --iw 1 keeps the generated image very similar to your original image.
I can’t guarantee this does much, but try cropping the prompt image to 256:256 and maybe touch them up to emphasise the parts you want Midjourney to take notice of.
/imagine less of this ::0.5 but more of that ::5
If you prefer, work with percentages. (My brain does better with percentages.) Don’t use the percentage symbol, though. That doesn’t work. Instead:
/imagine apple ::80 orange ::20
(for 80% apple, 20% orange)
Also this:
dog:: cat:: = is dog (once), cat (once), averageddog::2 cat::2 = is dog dog (twice now) cat cat (twice now), averageddog::4 cat:1 = dog dog dog dog cat, averageddog::1 cat:3 = dog cat cat cat, averaged
Something::1Lightly Something::0.5Eliminate Something::-1
Messing around with image weights is sometimes necessary because Midjourney has some quirks. Like… eyes:
IMAGE WEIGHTS
As mentioned above, Midjourney lets you tell it what you what by reading a url to an image. Compared to how well the text prompts work, it’s surprisingly not that great right now.
However! With a lot of re-rolling (like maybe ten times?) I did get from this cartoon portrait of Lisa Simpson:

To this 3D realistic portrait of Lisa Simpson:

But the eyes are creepy and I could not for the life of me manage a white pearl necklace so I retouched in Affinity Photo (took about five minutes):

Here’s the prompt that got me there, but don’t ask me whether the image weight instruction actually works, I don’t know (I used a smaller version of the cartoon of Lisa Simpson above in this prompt):
/imagine [ENTER] realistic girl, lisa simpson, detailed, short spiked blonde hair, large eyes, large pearl necklace, portrait, unreal engine --ar 2:3 --iw 1.5

For comparison, here is the Lisa Simpson I made with Stable Diffusion one month later for free, after installing Automatic 1111. (Retouched in Affnity Photo.) I’m finding Stable Diffusion does a better job of returning human ages you ask for. Here I asked for an 8-year-old. Likewise, Stable Diffusion gave me a 40-year-old woman who actually looks 40. Importantly, those 40-year-old women weren’t all white.
Irony: Stable Diffusion has been trained on more p*rn, so I’m not saying it’s less biased than Midjourney. It’s just… biased (and sometimes awful) in a different way. (On release, people immediately started using it for nefarious purposes. My AI art Twitter feed completely changed.)
Stable Diffusion doesn’t recognise the 3D engine prompts. I used the name of a famous portrait photographer to get the realistic look.
Yeah, but here’s the true test. Can I also make a Homer Simpson?

I kept getting a whole lot of dudes who look like Jane’s dad off Breaking Bad.

For some of those I used the prompt ‘smiling’. Do you think I could get him to smile? No. Midjourney is drawing from 3D models (which I asked for when I included ‘unreal engine’ in the prompt). If you’ve spent any time at all on those 3D engines, you’ll know there are two main types of people: Young attractive and sexually appealing women, and old cranky men from the cast of Game of Thrones. Maybe if I’d used the term schlubby I’d have got a better result. But I used this one:
/imagine [ENTER] realistic middle-aged man, homer simpson, detailed, comb over hair, large eyes, five o'clock shadow, portrait, unreal engine
I had trouble getting to Homer. Gave me a bouncer/boxer dad. I had to put ears and a white shirt on him myself. But at least he’s smiling! He’ll do until the real Homer shows up.

When using image prompts, people on the Discord server advise to resize prompt images to a 1:1 square. So if you submitted a 16:9 landscape, it’ll get squashed. (I predict image prompting will get better soon.) For now, try to use squares as prompts, or something close to a square?
For a comprehensive run-down see this Google Doc: Understanding Midjourney Prompt Combinations and Weights. (Contains pictures. Experiments are done on an AI generated teapot.)
That document is really super detailed and if you need to generate an art directed image, learning image weights will be of benefit.
If you’re looking for 20th century illustration (in particular) click on the Art category of this blog. I have collections such as:
- Illustrating metallic surfaces
- Sunset and Sunrise
- Water Surface
- Boats
- Ships
- Trains
- The colours of bright, sunny days
- The beach
- Moons
- Cake
- Still life flowers
- Various still life
- Fairies
You’ll find things like that on Pinterest as well, but I also collect images according to composition precisely for the purpose of AI art generation:
- An Entire World In A Single Illustration
- Two Worlds In The Same Illustration (e.g. underground and above ground, over water, underwater
- The Peephole View (looking through trees, out of cave entrances and so on)
- Interesting foregrounds
I also have some less common illustration collections:
- Washing lines and washing work in art and illustration
- Crowd scenes
- Aerial views of beaches
- The beach at night (scroll down)
- One-point perspective picture book houses
- Large Shapes
- The suburbs
- Haystacks
- Animals riding other animals
- Little Red Riding Hood illustrations
- Naïve illustration
- What I call ‘sticker sheet’ or ‘collage sheet’ composition
- Favourite fairytale illustrations
- Liminal (between) spaces
- Garden paths
- Shiny fabric
- Young men picking up their dates
- Parties
- Thick outlines
- Thin outlines (atomic illustration)
- Heavily curved horizons
- Views of rivers from the middle of rivers
- Cartoonish and highly stylised cats
- Unappealing cats
- Hunting dogs
- Frogs and Toads
- Elephants
- Fantasy laboratories
- Lanterns and street lighting
- Checkered floors and backgrounds
- Villages
- Symmetrical, slightly creepy, English style gardens
- Storybook farms
- Movement toward the viewer
- Weddings
- Glow worms and fireflies
- Lighting inside the home (through the ages)
- Table scenes with a whole lot of different perspectives
- Ships in dry dock and harbour
- Hunting and trapping
- Cooking over campfire
- Balloons and bubbles
- Kitchen stoves
- Windmills and Water Mills
- Aeroplanes in composition
- Catching fish
- Housework
- Carriages, carts, chariots, coaches
- Buses
- Underwater scenes
- The haze of hot summer days
- Young women running way from castles at night
- Interesting shadows
- Ominous faces in shadow (interesting portrait lighting)
- Bees and wasps
- Interesting use of negative space
- Trick or Treating
- Dark, shadowy interiors
- Women and their cats
- People with their arms hanging off the bed
- (Mostly) Women and girls reading
- Bookshops
- Alleyways and other views between buildings
- Motorcycles
- Vintage cars
- Volcanoes, magma, lava
- Tree houses
- Girls and women having fun
- Table scenes from Alice In Wonderland
- The Gingerbread House from Hansel and Gretel
- Baking in the kitchen
- The town square
- Fences
- Stones, Rocks, Paving
- People kissing
- Compositions with strong vertical divisions
- Sunlight streaming into rooms
- Cities under snow
- Houses in the snow
- Snowy landscapes
- Lighthouses
- Slopes and hills
- Snowmen
- Pre-Christmas vibe
- Post Christmas moods
- Krampus, Saint Nicholas, Santa
- Creepy Victorian Christmas postcards
- The forest at night
- Smooth, simplified surfaces
- Many different ways of illustrating the sun
- Illustrations with castles in the distance
- Castles
- Fruit, flower and vegetable picking
- Art studios
- Signage
- Storms, rain and wind
- Ship decks
- Numerous “birds” roosting in trees
- Crocodiles and alligators
- Uplit faces
For interesting palettes of specific colour:
- Green
- Purple
- Pink
- Orange
- Red and Blue
- Red, Blue and Yellow
- Yellow and Black
- Various different coloured skies
- White streets, blue skies, blue seas
- Warm yellow windows which look cosy from a distance

ADDING WEIGHTS TO WORDS
Adding weights to words with
credit to Ivan Mickovski on Facebook (see more of his tips on Reddit)::ncan significantly affect the result. Same with--iwn for images. A value of 0.5 will result in taking some small elements, a few shapes and colors, into the resulting image. But the words will take precedence. A value of 10 is almost like telling Midjourney to give you a new version of the image prompt while disregarding any words.
WRITE PROMPTS LIKE YOU’RE TAGGING AN IMAGE FOR ACCESSIBILITY
a woman sitting at a table inside a 1970s kitchenan antelope runs across a plain
Prompt engineering tip. Instead of: —Imagine the output you want —Specify its attributes to the AI Try: —Imagine that you already live in a timeline where the output you want exists —If you were using/quoting it in a blog post, what caption or context might you write for it?
@davidad
There are resources on the web about how to alt tag for accessibility. Here’s a good one. Advice applies equally to Midjourney.
Interestingly, the crossovers between prompt engineering and alt tagging for accessibility go further than you might expect. For example, telling someone who has been blind from birth that a man is wearing a red hat isn’t going to be useful to them. What is red? Likewise, Midjourney doesn’t find ‘red hat’ useful either (at the moment). Midjourney knows the colour red exists, and that it is a colour, but clearly doesn’t know what you mean by ‘red hat’.
Prompt engineering tip from @davidad on Twitter:
Instead of:
/imagine the output you want
specify its attributes to the AITry:
Imagine that you already live in a timeline where the output you want exists
If you were using/quoting it in a blog post, what caption or context might you write for it?
Corollary: praise is useful, but specific or realistically-phrased praise is better than generic praise
THE ‘MIDJOURNEY’ LOOK: REDS AND TEALS
Midjourney has a look. Unless you add prompt images, artist names, and further specifications, you end up with something like below. Reds and blues with yellow tints proliferate. (The algorithm is probably drawing heavily from primary colours.) There’s a dreamlike, fantasy quality to it. Everyone will soon recognise this as Midjourney’s default style. (Until it evolves, that is.)
Someone on the forum has worked out why these colours proliferate. Basically, you get reds and blues (or oranges and teals) when Midjourney doesn’t recognise your style, or if you haven’t set one:
How to check first if Midjourney even understands your sourcing reference:
- You want to say in the style of Ren & Stimpy (for example) but you don’t know if Midjourney will understand that.
- You think about something that appears commonly in that style. For example, something that appears often in Ren & Stimpy is a cartoon chihuahua (that’s Ren himself).
- Do this simple test:
/imagine a cartoon chihuahua in the style of Ren & Stimpy - If output looks like it’s adopted the style you named, you’re golden. 👎 If it appears generic with lots of orange and teal colors, you’re looking at Midjourney ‘defaults’ which is an error message meaning NOT FOUND.
See this red and blue palette in action below. I tried messing around using lines from poet Emily Dickinson.

Naturally, Midjourney is perfect for making those inspiration images you see all over social media.

If you ask for retro color you get the same palette but warmed up:

After lots of experimentation, I’ve come to this: Unless you specify something in the prompt to guide Midjourney away from the primary colours, you’ll get the Midjourney Palette.
This will get you the Midjourney Palette:
/imagine [ENTER] suburban houses
This sort of thing will move move you away:
/imagine [ENTER] suburban houses, realism, unreal engine
/imagine [ENTER] suburban houses, studio ghibli
/imagine [ENTER] suburban houses, [NAME OF ARTIST] style
I’ve tried to use a palette as a prompt (from the free Coolors website) but there’s no --iw which will magic you up the perfect combo of “take the colors from this image but don’t take anything else!”
I hope this changes in future. In the meantime, people are trying to art direct colour in various ways. e.g.
Q: Is there a way to emphasize a color when I specify more than one color in the prompt? Like if I say red, white and blue, can i make white take up 75% more screen space than red and blue?
A: I saw someone hyphenate strings of words that are meant to be specific, and that’s consistently helped me out with THAT aspect of prompts. For example
girl with long-pink-hairordusty-rose-color-hair(addingcolorso it doesn’t start flowering those hair follicles) andred-jeepfrom the Discord chat
Red::1 White::2 Blue::3will prefer blue over white over red.

USE THE LANGUAGE OF PHOTOGRAPHY
a close up ofextreme closeupmacro shotchiaroscuro— the use of strong contrasts between light and dark, usually bold contrasts affecting a whole composition. It is also a technical term used by artists and art historians for the use of contrasts of light to achieve a sense of volume in modelling three-dimensional objects and figures.a Canon EF 50mm photograph portraittimelapsesharp focus- focal lengths — @davidad tells us: “You can prompt for specific f-stops and focal lengths. Here I generated
an orchid at f/1.8, then used inpainting over the out-of-focus parts to get roughly the same shot atf/5.4,f/9, andf/14.”
Good luck direct Midjourney when you want a specific angle, but you can give it a whirl!
See: 12 Camera Angles to Enhance Your Films (YouTube)
ASPECT RATIOS
By default, Midjourney gives you square artworks. But you can change this really easily.
--ar width:height
Be mindful about your aspect ratio. The algorithm will use the canvas and fill it, so if you want, say, a tall skinny house, create a tall skinny canvas. (This Facebook post shows examples of that using generated images of Notre Dame.)
Portraits on images with ratios with room to fit more than one face sometimes develop extra faces or facial features. (You may have noticed this phenomenon if you’ve used the app “This Face Does Not Exist”.)
If you’re creating a vintage image, an aspect ratio of --ar 8:10 is a vintage size. If you’re creating a contemporary image, an aspect ratio of --ar 8:12 is what you get out of modern cameras.
If you’re hoping to print artworks out and get it framed:
COMMON STORE FRAMING SIZES (in inches):: =--ar 4:5 (8×10 & 16×20)--ar 1:3 (11.75×36) … it’s really 1:3.06 = 47:144--ar 11:4 (16.5×6)--ar 11:14 (11:14 & 22×28)--ar 3:4 (12×16)--ar 13:19 (13×19)--ar 7:9 (14×18)--ar 3:8 (18×24)--ar 5:6 (20×24)--ar 2:3 (24×36 & 20×30)
WHAT DOES 4K AND 8K MEAN?
You’ll see other people adding 4k and 8k to their prompts. What does it do?
This is from the world of TV, cinema and monitors, and refers to resolution. What does it mean for Midjourney, though? People tend to use these resolutions as tags on desktop wallpaper sites, so using this prompt in Midjourney will encourage the algorithm to draw on high quality images people tend to use as desktop wallpapers.
TYPES OF LIGHTING
For the best results, be sure to include information on how you want light and shadow to work.
Experiment with:
dim lightsoft lightharsh lightwarm lightingcool lightingcinematic lightingdim lightingcandlelitvolumetric light(“God Rays” or Crepuscular Rays, beams of light)dramatic neon lightingstrong shadowshard shadowsbioluminiscent(like those jellyfish that glow)noirdescribes a type of lighting as much as anything (chiaroscuro — strong lights and darks). I’m getting nice results with ‘realistic noir’.

TYPES OF LENS
Telephoto of a(A telephoto lens is a long-focus lens which brings distant subjects closer. When talking to AI, you’re asking for an image that is ‘zoomed in’, say a lion but without a mountain vista behind it.)distant view of
DEPTH OF FIELD
Depth of field is the distance between the closest and farthest objects in a photo that appears acceptably sharp.
shallow depth of field(A small circle of focus. The foreground object might be in focus but everything in the background blurry. Popular for portraits and macrophotography. The subject stands out from the background.)deep depth of field(Everything in the image is the same amount of focus. Sharp from front to back. Popular in landscape, street and architectural photography, where artists want to show every detail from the scene.)macro photo ofaerial view of a

INSIDE OR OUTSIDE?
interior ofin a roomexterior of
USE THE LANGUAGE OF TRADITIONAL ART
still lifeportraitlandscapecityscapeseascape
MOVEMENTS
You can find art movements on Wikipedia or head over to NightCafe Studio for a full and expansive list. (NightCafe Studio is another AI generator. It gives you a whole heap of options for prompts when you hit ‘Create’.)
realistic art decoart nouveau
Others have compiled super comprehensive lists. Try Wikipedia categories. E.g. Art Movements.
MIX AND MATCH MOVEMENTS WITH STYLES
Surreal Fantasyanime styleabstract painting ofpainterlyhighly detailedmaximalist(Super detailed, busy — ‘a movement against minimalism)hypermaximalistin the style of a WW2 recruitment postertourism poster in style of Bauhausmedievalflat designJapanese paintingpinup girlVictorian paintinginspired by cartographic mapsschematic of asketch ofphotograph ofsteampunkRenaissance



/imagine [PRESS ENTER HERE] cats in disguise, silk screen printing
Images below have been lightly retouched and cropped. I actually wanted dark trees framing the foreground, like, really close, World of Goo style, but I liked what it gave me anyway:



/imagine [PRESS ENTER HERE] landscape with dark trees in foreground, eric carle, lotte reiniger
Note that the modern era of Internet has given us a whole lot of styles which don’t appear in official lists of ‘art styles’. (See the link up top for the Aesthetics Wiki.) Aside from that, we’ve got:
selfie(often gives you the arms)knolling(That top-down view people use when making YouTube videos of cooking demos. Sometimes knolling will give you items inside a cardboard box. From unboxing videos, I guess?)
A number of people are wanting their art to look like their favourite games and movies:
fortniteready player onered dead redemption
/imagine [PRESS ENTER HERE] school yard in the style of red dead redemption --ar 3:2



FAMOUS ARTISTS
in the style of [ARTIST NAME]works welldrawn by moebiuspainted by Goya during his black periodby gustav klimt fine art painterlylovecraft(actually a writer, but one who continues to inspire many artists)bauhausstyle painting(a German art school operational from 1919 to 1933 — this prompt works really well)in the style of studio ghibli(an animation studio rather than a single artist — hugely influential)in the style of steven universe



FOOD PROMPTS FOR MIDJOURNEY
I felt like making some food out of a Studio Ghibli film. Like faces, food can be difficult. Artificial intelligence doesn’t need to eat, and has a history of making food look disgusting.
(Try this Random Food Generator for prompts.)
This caramelized broccoli stew is fairly tough with a sugary texture. It has subtle hints of red potato with marjoram and has anise. It smells fragrant with an overwhelming amount of cress. It is sweet and delicate.
Random Food Generator
For photorealistic food, try describing the food you want alongside the language of food photographers.
Try all or many of the following:
High resolutionhypermaximalistcinematicoverdetailedfood photographysaturated telephoto photoextremely detailedextreme close uphdrcanon mk5canon 5d55mm lens- the name of a famous restaurant e.g.
el bulli molecular gastronomymagazineaward winningdecadentfruit texture- a description of crockery and cutlery e.g.
glass, spoon

Anyway here’s what Midjourney did with my request for eggs on toast:

I asked for more variations on number one. (What are those blue dots? The things Chihiro eats in Spirited Away, which make her stay in the world?) Here’s what it gave me next.

I hit Upscale on number four. What do you think of the result? I don’t think it’s quite Studio Ghibli level delicious but Midjourney did a better job of food than I expected!

Norman Rockwell was a hugely influential American painter. Somehow the illustration below looks like it was done by Rockwell, even though it completely messed up the faces. (The food looks… disgusting this time. But maybe that’s what Midjourney knows aliens eat.)

Then I got obsessed with aliens.
/imagine [ENTER] aliens at the cinema



WELL-KNOWN INTERNET FORUMS WHERE YOU FIND A LOT OF ART
artstation(a massive art-sharing site)trending on artstation(It’s not entirely clear whether ‘trending on’ does anything, but many people are using it.)digital artis a good catch-all term
USE THE LANGUAGE OF DIGITAL ART/FILM-MAKING
POPULAR adobe PLUG-INS
To learn what these do, best to look for examples on the Internet because they’re impossible to explain in words!)
slitscan(an AfterEffects plug-in)post-processed
RENDER

octane render(This means you want the AI to use art in which base images used the famous Octane graphics card to render photo-realistic images super fast. It basically means ‘photo-realistic’.)redshift render(Redshift: “The world’s first fully GPU-accelerated, biased renderer”. Click through to the website to see the sort of images the algorithm will be using. Basically, photorealistic 3D.)unreal engine(a 3D creation tool which will conjure art made with it. This tends to be photorealistic, fantasy, with lots of mood lighting, so you’re really asking the AI to convey a certain mood.)toon boom render(a Canadian software company that specializes in animation production and storyboarding software)- chaos
vray render(used for all sorts of things including building interiors) bryce render(also often referred to colloquially as Bryce3D, Bryce is a 3D modeling, rendering and animation program specializing in fractal landscapes)physics based rendering(a computer graphics approach that seeks to render images in a way that models the flow of light in the real world)
The reason I had to specify mason jar is because it kept giving me things like this:


I made the mistake of asking for brain and eyes KEPT ALIVE in a jar and the algorithm thought I wanted a face (as well as the brain and eyes):

I also wanted an illustration for Roald Dahl’s “The Ratcatcher”. The main character is part man part rat. Can Midjourney do that?
The first dude looks the spitting image of Grant over the back fence after he’s been working in the shed, and realised he can’t fix his own car after all. Awkward. The third one looks like Goth Nana’s gruesome knitting project. That second one, though! That’s exactly what I want. Stuff of damn nightmares.


Can you turn anyone into part man, part animal? YES.

I had a bit more trouble turning a man into a flower. I kept getting flowers with men, which is lovely.
/imagine [ENTER] part man part flower, unreal engine, portrait, detailed, realistic



But I was after something way more creepy than that. So I looked up ‘parts of a flower’ and incorporated the technical terms. (Note: Although I used ‘portrait’ as prompt, I messed up the aspect ratio, got it back to front. Should’ve been 2:3 for portrait, not 3:2):
/imagine [ENTER] cryptobotany man shaped like a flower peduncle, sepal, petal, stamen, pistil, anther unreal engine, detailed, realistic, portrait
This gave me some alien landscape botanical specimens, but NOT PART MAN PART FLOWER. Which is what I’ve decided I need.
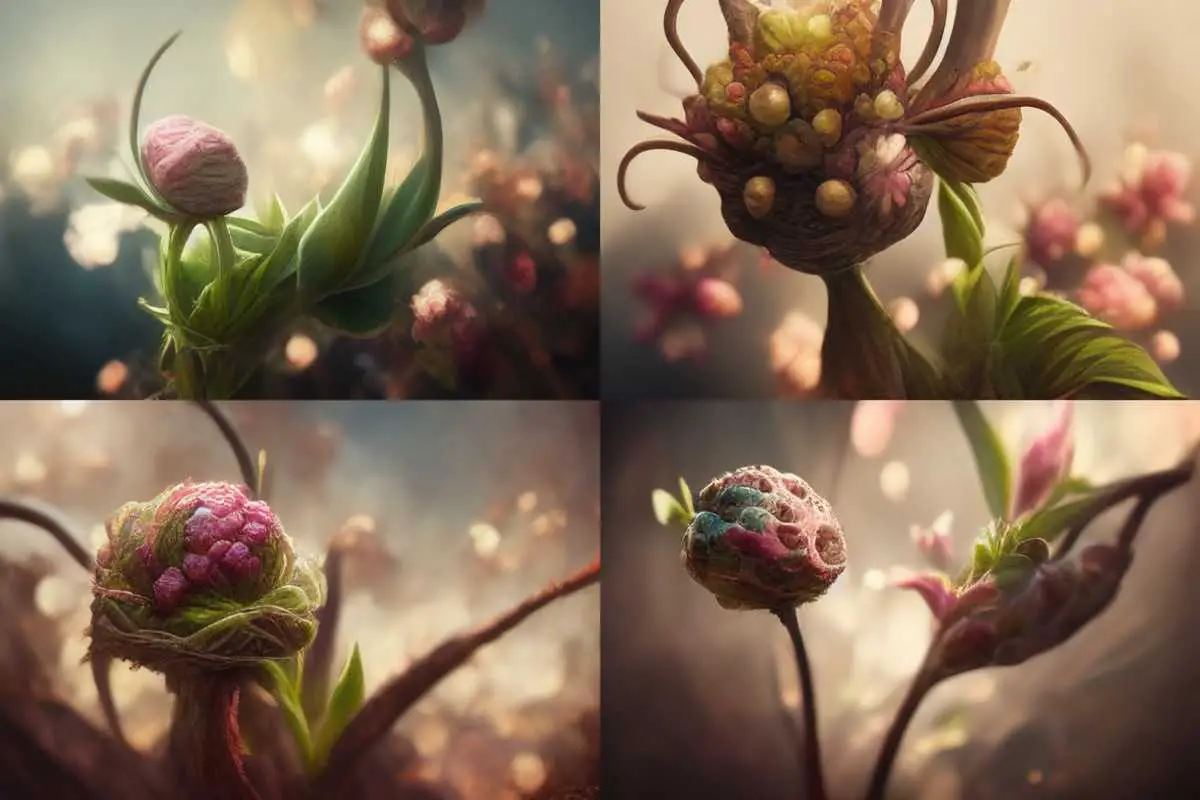
Next, I decided to use the magic word. CRYPTOBOTANY is the magic word, folks.
/imagine [ENTER] cryptobotany man shaped like a flower peduncle, sepal, petal, stamen, pistil, anther unreal engine, detailed, realistic, portrait
Now we’re cooking with gas. Number four is getting closer.



Soo… what happens if I use the cryptozoology when I’m making my part-man, part-animal portraits? Will that do anything? I’m very happy with the half-man half rat I already have, but what happens if I shove the word cryptozoology at the start of the same prompt?
/imagine [ENTER] cryptozoology, half man half rat, portrait, detailed, unreal engine, realistic
I kept re-rolling. Not obvious from seeing these final thumbs, but very obvious watching the progress images: The word ‘cryptozoology’ returns images of bigfoot. I deduce that’s because the word ‘cryptozoology’ and ‘bigfoot’ go together so frequently. (Less clear: Why did I get Grant from over the back fence, again? Why do the same people keep cropping up in certain prompt combos?)




Try also: creature anatomy.
/imagine [ENTER] creature anatomy, pebbles, photorealistic --ar 3:2


/imagine [ENTER] creature anatomy, perfume bottles, photorealistic


/imagine [ENTER] tall humanoid made of the universe --ar 2:4

/imagine [ENTER] tall humanoid made of power pylon --ar 2:4

USE THE LANGUAGE OF COMPUTING
bitmaplow frequencyglitch art
/imagine [ENTER] bitmap, suburban street at night --ar 3:2


/imagine [ENTER] low frequency, suburban street at night --ar 3:2


/imagine [ENTER] glitch art, suburban street at night --ar 3:2


USE THE LANGUAGE OF BUILDING AND ARCHITECTURE
Once again, don’t forget Wikipedia has categories. Here is Wikipedia’s list of architecture categories, with way more architecture words than a person could ever use. It gives you lists of woods, roof shapes, building materials, architecture in Europe, you name it.
eco brutalist apartmentfantasy castleneoclassical architecturedimensionsymmetrymedievalold ruinsabandoneddark tunnelflat roofmade of tungstencarved from sapphire stonecurvilinearwooden house--no triangular rooffrank lloyd wright stylearchitectural section(interesting when applied to things other than buildings — this is a type of diagram where someone has sliced into the thing to reveal a cross-section)colossal gothic dystopian sci-fi skyscraper apartment carved inside gray granite canyon, sapphire gothic stairs carved into the canyon, gothic stairs in front of the building and around it, many gothic people climbing up and down stairs, gothic medieval palace castle ornaments, isometric --ar 1:3 --q 5giant modern smart futuristic lovecraftian building architecture, MC Escher, transversal section, 8k, ultra detailed, octane render, realistic --ar 9:18
Think broadly when considering materials:
made out of hundreds of scissorsmade of ice cube with black and red berries inside
A quirk of Midjourney: Where an image includes both architecture and trees, you tend to get trees coming out of the roof.


Midjourney won’t reliably take art direction for camera angles. But after a bit of experimentation, I realised the prompt high on a hill is likely to give you shots like this. It thinks you mean ‘as viewed from a hill’ (even though I wanted the house itself to be on a hill).
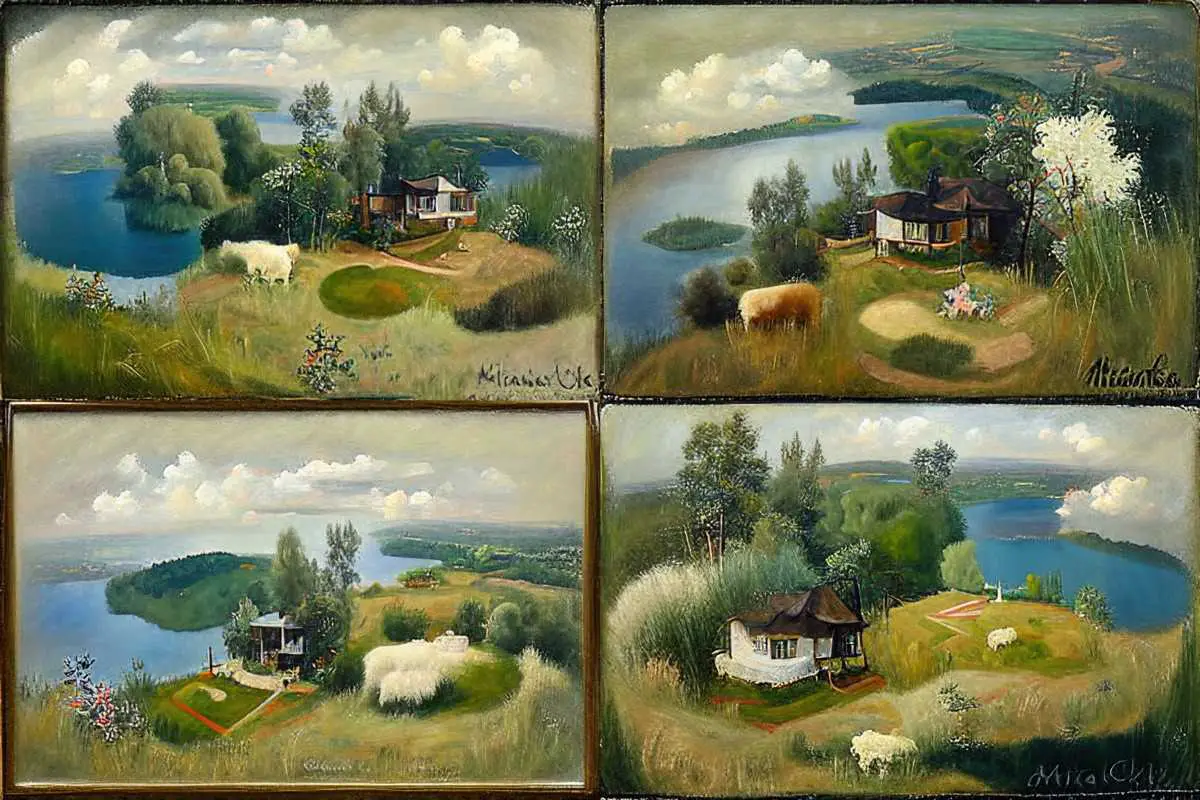
Let’s try some other experiments.

/imagine [ENTER] the white house in the style of Hayao Miyazaki bath house from spirited away

CREATING ORNAMENTS
The word baroque returns good results.
baroque Italian pastel marble statue ofbaroque [X] made of ornate gold and pearla [X] statue, baroque, ornate, highly detailed, gilded, soft lighting, unity engine, octane renderA crystal with a [X] inside of it, render, realistic, cgi, cinematicopalescent [X] in the shape of a [Y]baroque bejeweled [X], ornate, intricate, detailed, with gold filigreecrystal form
But I’m finding a lot of re-rolls are necessary to get something good. My ornaments are crap. I think you need to increase the --q parameter. (Default quality is 1. At time of writing, 5 has been disabled. Try --q 2. It costs more time credit.)
These pineapple statues aren’t quite there:
/imagine [ENTER] ornate baroque Italian marble statue of pineapple


TELL MIDJOURNEY WHAT YOU WANT IN THE BACKGROUND
Midjourney doesn’t take art direction when it comes to perspective. Unlike a human artist, you can’t reliably tell it if you want a side-on view, a low-angle, oblique view and so on. But you can get some of the way there by telling it what you want in the background. (Also, sometimes it does do what you want when you prompt with something like ‘low angle’, ‘a wide view from behind’ etc.)
sitting on grasslandin flower fieldin vast field of poppiesin empty roomin the middle of a town squarewith forest in backgroundin wildernessroaming the barren plainson a wooden tablebokeh backgroundon a small and quiet lake in a dense pine foreston the edge of a frozen canyon surrounded by alpine forestmetaverse (describes a virtual-reality space in which users can interact with a computer-generated environment and other users)
TELL MIDJOURNEY WHAT TIME OF DAY YOU WANT IT
Meaning where you want the sun (or moon).
golden hoursunrisein the middle of the nightshimmering colourful night skyunderneath a moonlit starry dark night skysunlight filtering through the treesrays of lightbeautiful raking sunlight
ORDERING THE PROMPT
A command has two basic parts to it:
- PROMPT (the keywords and description)
- SETTINGS (settings to last)
- Name the Item (what you’d find if you looked it up in a dictionary)
- Describe the item (what it’s made of, its texture, decorative detail)
- Style of the art (genre of art etc.)
- Describe the art (This is where your aesthetics terminology comes in handy. Move away from what you’d find in an art book or on Wikipedia and describe it like you’d describe it to friends, or how people describe things on ArtStation e.g. ‘crazy detail’)
- Photography, mood and composition terms.
So, what it looks like right now: If you load too much info into 1. and 2 (the prompt) you’ll only confuse the algorithm. But you can really go to town on 4. and 5 (the settings).
Here’s another perspective, though I ripped this from the NightCafe newsletter, which makes use of Stable Diffusion, suggested by popular user Adamsito:
—Main subject
—Secondary subject
—Artists’ names/style
—Photography/artistic prompts
—Specific colors (optional)For example:
The NightCafe newsletterA deer passing through(main subject)an abandoned neon city(secondary subject), byDan Mumford and Victo Ngai (artists’ names),8k resolution, a masterpiece, 35mm, hyperrealistic, hypermaximalist(photography/artistic prompts),crimson, jade(colors)
(This user highly recommends adding the word masterpiece to your prompt. Try it out, what do you think?)
CONVEY THE MOOD
a dark morbid(remember, no comma necessary when listing adjectives)cutekawaiichibi(means short/small in Japanese, similar to kawaii style)moodyetherealglowingfuturisticisometric(Also called isometric projection, method of graphic representation of three-dimensional objects, used by engineers, technical illustrators, and, occasionally, architects.)
Using the words sticker and sticker sheet and die cut sticker for character design inspo. None of these monster bananas below are quite right, yet, but I can see where I’d take them.
/imagine [ENTER] cute banana monster sticker sheet

EXPLAIN THE COMPOSITION
If you have a composition in your head and want the AI to paint that, you’ll have to try and explain that to a computer.
romantic comedy(gives you something based on a poster)LP albumhip hop album coverartstation album artbox office(movie poster)renaissance painting ofhorror movie posterhalf blueprint1970s postcardjapanese poster, printportraitwaist up photograph oflively movementheadshot(a close up of the face)ultrawide shotan expansive view offull color encyclopedia illustration offull page scan hi res technodetailed concept art lithographantique lithographleonardo da vinci drawing ofa map ofinfographicsgraph data knowledge map made by neo4jtarot card(this is a popular one — gives you symmetry and intricacy)
/imagine [PRESS ENTER HERE] canberra city in the style of Alphonse Mucha, tarot card --ar 2:3



THE PROBLEM WITH DESCRIBING COLOURS
UPDATE: Since writing this post, Stable Diffusion took off. If you want to art direct colours, use Stable Diffusion e.g. by installing AUTOMATIC1111 on your own computer, or by paying per image at DreamStudio. The colours will come directly from the artwork you upload.
MAPPING COLORS ONTO SPECIFIC OBJECTS
/imagine [ENTER] a black dog on the left :: a white dog on the right

I re-rolled. I got:
- One super long dog in a horse-ghost suit
- Two block dogs(ish)
- Getting closer. Except the black dog has dressed in a ghost-sheet for Halloween.
- Getting closer, except the black dog is actually a white Steve Jobs dog wearing a black polo.

Telling the AI which colour to make different objects doesn’t always work but you can try. I asked for a red swimming pool with a white house behind and it gave me a regular blue pool with a red house behind.
Although AI art generators cannot yet take instructions to make certain objects a particular colour, describing colour in more general terms (e.g. muted color) often works well.
DESCRIBING THE PALETTE
Other things to try:
red skymade with small to large irregular dashes of muted colorwarmblack-and-whitemonochromeat golden hourwater elementalpastel color stylewith gold filigreefull of golden layersbronze-scaledretro palettevarious gradient colors(tryombrealso)
I tried using colorful in the prompt and got this (a palette which I always find truly extra). psychedelic gets you there, too.

MAKE USE OF STRONG EMOTIONS
The manual tells us to use the language of strong emotion. This has the effect of making the prompt vague.
There’s also a cognitive bias at work here: When we input something vague, we tend to like whatever we get because we didn’t start with a specific image in mind. The AI can only surprise us in a good way.
So, if you want an illustration to accompany a story, pick the story’s theme, turn it into a partial sentence and go with that. Or try a line from poetry, your favourite song lyric.
/imagine [ENTER] baba yaga’s spooky cottage in the style of albert chevallier tayler


MAKE USE OF ADJECTIVES
a hyperreal portrait of [person] looking regal and confidentgirl with a cheeky smileangry and cocky facial expression
Midjourney seems to understand ‘cute’ but doesn’t know what ‘beautiful’ means. When creating portraits, use symmetry as a prompt. artbreeder also works.
One thing I’m glad of (for now): Midjourney bans use of this tool for making naked renders, but in future of course we’ll see dedicated AI porn generators. Not for a while though, because Midjourney does a horrible job of generating people. (Also bikes, horses and things like that.)
The Midjourney team have also banned a number of words associated with violence. For instance, you can’t use ‘blood’ in a prompt. (Say ‘red paint’ instead.) ‘Cutting’ is also banned, which is annoying because I wanted to make some paper cutting art.
Here’s how that experiment went.
TELL MIDJOURNEY WHAT ART MEDIUM TO USE
And perhaps what paper/canvas to paint on:
expressive gouache illustrationpaintacrylicoracrylic on canvasoiloroil on canvasimpastoandpalette knifewatercolorrealistic, highly detailed watercolorwatercolor and inkmanga cover, sharp drawing, ink, coloredsumi-eukiyo-ewoodblocklithographpaper crumpled textureorigamipaper quillinga paper diorama of X, construction paper textureon cardboard canvas
ORDER OF WORDS: DOES IT MATTER?
Words closer to the beginning of the prompt seem to have a greater effect on the result, except if the description is too long, and then it seems to forget what came first (in my experience).
STOPPING YOUR IMAGES EARLY
--uplight is a parameter, not a prompt, and does not refer to photographic ‘uplighting’. It means you want the upscale to add fewer details. (Must be short for light-handed upscale.)
Alternatively, try early stopping your imagines with --stop 90
Why would you want to do this? Oftentimes the generator keeps going just a little too long. The 90 refers to 90 per cent of what the generator would’ve done. You can of course knock it back further for a more simple design.
See the difference in the images below.
/imagine [PRESS ENTER HERE] a tiny castle floating in a bubble above a suburb, studio ghibli style
The thumbnails came back like this. Although it has decided to ignore my request for ‘above a suburb’, I like number four. So I hit upscale on that.

When it was 90% done I hit save. (If you do it like this without specifying parameters, which is like watching a pot boil, the image saves as an HTML, by the way.)


Studio Ghibli generations look better at 90% because they are more smooth. (Probably applies to other anime and manga styles, too.) Can you see now why you want photo editing software with retouch capabilities? My fave is the inpainting tool.
Try combining different but similar styles, e.g. your favourite animation studio with your favourite game.
Try using a prompt such as lofi, digital art. That might give you what you want, regarding the lower level of detail.
(Add guitars to the list of items AI cannot yet draw.)


DEALING WITH SYNONYMS AND ASSOCIATIONS
Say you’re trying to make a portrait of a man but Midjourney keeps giving you facial hair. Try --no moustache, beard
Midjourney doesn’t understand boundaries and does not always listen to --no.
You see a lot of facial hair on Midjourney men. Seems the best way to avoid it is young man. But not all middle-aged men have facial hair!
CREATING MINIMALIST ARTWORK IN MIDJOURNEY
Maximalist works proliferate among enthusiasts of AI. Fewer people are generating minimalist art on purpose. So why not buck the trend?
Try adding minimalist cinematography to your prompt.
/imagine [ENTER] suburban street at night, minimalist cinematography --ar 3:2


Let’s lowering the stylize setting to 625 or 1250. Wait, what’s ‘stylize’ mean, you ask? I haven’t mentioned that one yet. Here’s the screen cap from the Midjourney User Manual:

The default setting is 2500. That’s enough styling for Midjourney to think it’s got carte blanche to make everything extra. Let’s knock it back using the --s parameter.
/imagine [ENTER] suburban street at night, minimalist cinematography --s 625 --ar 3:2
I definitely see the difference in the thumbs.


While we’re talking about stylize, let’s investigate what those higher stylize settings do with the same text prompt. I’ll knock it right up to 20k. Type it like this:
/imagine [HIT ENTER] suburban street at night, minimalist cinematography --s 20000 --ar 3:2

Now let’s knock it all the way up to 60000.
/imagine [HIT ENTER] suburban street at night, minimalist cinematography --s 60000 --ar 3:2

Well, the documentation wasn’t wrong. ‘S’ may stand for ‘STYLIZE’ but it may as well stand for ‘SURPRISE ME’.
I like to think of Midjourney as a designer’s assistant, on drugs. Using “
@JohnnyMotion--stylize” lets me modulate the drugs that my assistant is on!
CREATING FLAT DESIGN
You know that flat design which is so popular? The prompt you want is ‘vector art’ or ‘smooth vector’ if you want non-delineated gradients.
Try also: 2D matte illustration
/imagine [ENTER] suburban street at night, 2D matte illustration

As I was watching this upscale cook, I realised I’d have got a flatter design by stopping at about 60% (--stop 60).

/imagine [ENTER] suburban street at night, smooth vector


What if I use the word ‘gradient’? Make any difference?
/imagine suburban street at night, gradient vector
Yes, I definitely see a difference.


OCCLUSION WORKS BETTER THAN LINE ART
I’m yet to see Midjourney make a good job of anyone’s line art. Not even when invoking the great illustrators, famous for their line work. Line artists, your jobs are safe for now. Midjourney’s line art may look fine at a small dimension and low resolution, but does not stand up to close inspection.
However. There is something Midjourney is pretty darn good at. This sort of thing:
What’s the magic word? Well, one of them is “occlusion.”
/imagine [ENTER] back yard at night, black and white dark comic style, hd, environment, atmospheric, occlusion, minimal
Ambient occlusion is the soft, subtle shadowing that happens between objects that are in close proximity with each other, especially in tight spaces where light cannot easily reach. Illustrations with “occlusion” are not separated by hard lines. Instead, shadowy forms are merely suggested.
Anything you can do to soften the edges of a busy scene will work to your advantage in using Midjourney. magical and eerie atmosphere have the same effect, and will return that blue/red Midjourney palette (with a few black and whites thrown in for good measure).

Fog is the thing. If your illustration happens to require fog, you’re in luck. Fog hides a multitude of sins.

ABSTRACT ART
Let’s stick with the school at night theme and try out some abstract art styles. I discovered the combination of comic style plus the name of an abstract art movement returned very nice results. Without the abstraction, a school at night (or a kitchen, or a theatre etc.) will likely return messy scenes of tables with three legs, walls failing to align etc.







Fauvism returned the brightest colours.
Fauvism is what you get if you take Post-Impressionism and put it on Expressionist steroids through a Technicolour lens.
Hannah Gadsby, 10 Steps to Nanette


Neoplasticism returned some interesting results, each quite different. I like how one of them used two buildings as a frame. The image with the tables is a little messy, but the tables at least look like tables.



Geometric abstraction is pretty interesting, too:




Kandinsky (the artist, not a movement) has such a distinctive and recognisable style it’s impossible to use him as a prompt without the image shouting, “Kandinsky has entered the building!”

STAINED GLASS WINDOWS
I also discovered Midjourney is excellent with stained glass windows. Not all the time (Ernie and Bert were an unsuccessful experiment) but lovecraftian stained glass was a big success. I added the word renaissance and got a less digital look.


TYPOGRAPHIC IMAGES
Some users are trying to get Midjourney to design font for them, or decorative lettering, or to include the writing on movie posters. A fun challenge, maybe, but a fool’s errand for any serious work. Font design if an entire profession in its own right. Midjourney makes a horrible job of font.
What about typographic artwork, though?
In my experience so far, attempts to get a pretty poster with typographical elements are hit and miss. I’m not showing you my fails because they’re really ugly and bad. I have seen some excellent results but you do get a lot of rubbish as well, trying to create typographic art.
Try something like:
a monochromatic infographic posterText Desired : type : font : wordmark --aspect 16:9
(This person is using Wordmark as a prompt. Wordmark is a website that helps you choose fonts by quickly displaying your text with your fonts.)
Add prompts such as black line or single color to get a flatter result.
The best stuff doesn’t include font per se, but uses font as inspiration.




In 1971 Vangarde and Kluger released the cult LP Le Monde Fabuleux Des Yamasuki as the Yamasuki Singers, a pseudo-Japanese concept album of pop songs. The lyrics sound sort of Japanese but make no sense. Their most famous song is “Yama Yama“. (It’s very catchy, and also creepy.)
Likewise, Midjourney can create faux-East Asian typography for you.
PATTERNS
patternrepeatingfractal(s)generative artgeometricrecursivep5jsfabric wallpaper by William Morrisdamaskobsidian geodeswirlsseamless--tileafter your prompts to generate seamless textures (this means the images repeat if you use them as tiles). We’re seeing best results with--testand--testpbut it should work with all algorithm and creation flows (v1, v2, v3, upscale, variations, etc).”tile pattern(another common word for seamless)Infinite Mandelbrot-fractalsKaleidoscope texturevictorian eramathematicsnavier-stokes(equations which describe the motion of viscous fluid substances)fluid abstracttessellation(the covering of a surface, often a plane, using one or more geometric shapes, called tiles, with no overlaps and no gaps)mc escherspanish-inspired vector pattern 4k mosaic tilekorean traditional patternfloral camo(army camouflage, turned into flowers)



PROVIDE A TIME PERIOD
‘Retro’ works well. Providing decades also works well e.g. 1920s, 1970s.
in the style of a Baen science fiction paperback coverpolaroid of1940 vintagephotograph, colorizeautochrometintype(an old style of photo which looks black and sepia with a black, rough border and/or heavy vignetting)wet plate(another vintage style with scratchy textures)


ARTISTS AND MIDJOURNEY: COMPOSITION INSPIRATION
I typed the following into Midjourney:
/imagine [PRESS ENTER HERE] steampunk cafe, clean linework, magical atmosphere, honeycore
/imagine [PRESS ENTER HERE] steampunk cafe, clean linework, magical atmosphere, honeycore
Not bad, but unusably messy. I love how the lights look like giant droplets of honey. Would I have thought of that? Maybe not! If I spent a week on this I could make something really cool, not exactly from scratch, but tidying it up.

WHAT ABOUT COPYRIGHT?
Artists, especially digital artists, have long had trouble being taken seriously. Midjourney and other DALL-E 2 generators compound the problem: Even if artists spend many hours re-compositing (a.k.a. photo bashing), tidying things up, adding hand-drawn elements — even if we eschew AI inspiration for philosophical reasons, end users will soon assume every cool thing they see is made with AI now.
And I can imagine how client conversations will go down for digital artists from now on:
“You charge how much? I can get something that gives me, like, 90 per cent of these specs just by running keywords through an AI generator!”
Disgruntled ‘client’ goes away, but they still like artist’s style, right? So they run this favourite artist’s Behance folio through the Midjourney generator. Next, they pay someone a fiver to composite exactly what they need on a bootleg copy of Photoshop using uncopyrightable Midjourney generations which very much make use of the original artist’s work, which would be dodgy af, yes, even though an artist can’t copyright their style.

Most of the composition comes from this. Generally with a Midjourney generation, it’s a matter of making it simpler and firming up the edges. Eyes always need to be fixed.

I also took bits from these two generations:


The law is not currently protecting original content creators. What I’ve heard as a non-legal person: The artist who composited the Midjourney generation for a fiver does have copyright of the image because of the modifications they made. The modifications may be very minor. On the other hand, fixing something up can take a long time and high level photo software skills. So we shouldn’t undervalue that form of work, either.
https://twitter.com/PMxLEWIS/status/1555988708611870720
I mean, I love this tech. It’s here to stay. But I can also see its problems. Can we make a pact to use this thing as ethically as we can? If resources were spread more ethically, if universal basic income were a thing, artists wouldn’t be hung out to dry.
Some families have private inheritances, passing on their accumulated wealth. A Basic Income would be like a social inheritance, sharing the wealth that this society has created and eliminating deprivation for everybody.
Annie Lowrey, Politics and Economic Journalist
Jason Silva (storyteller/filmmaker) is all for it.
Wherever you fall on the ethical spectrum, let’s not start with the notion that the art world was fair and equal before AI stepped in. Sticking only to gender:
In the art world, there is a gaping gender imbalance when it comes to male and female artists.
In the National Gallery of Australia, only 25% of the Australian art collection is work by women.
This is far better than the international standard where roughly 90% of all artworks exhibited in major collections are by men.
Robert Hoffmann and Bronwyn Coate at The Conversation
FURTHER LINKS
Welcome to the Dawn of AI Art by John Lepore, who is conflicted about what AI generated art means for us.
The Unknown Power of AI to Maximize Your Creativity With Gene Kogan, an episode of The Rhys Show podcast. They dive deep into different generative AI interfaces such as Dall-E, Midjourney and Abraham the one he is currently working on, other generative models, how to create open-source systems and how they connect to collective intelligence and the environmental niches that AI is going to evolve into.
Here is the same show but on YouTube.
Here’s a Getting Started with Midjourney YouTube video with professional photographer Gailya Sanders. They start out explaining how Discord works. Even if you’ve used other chat apps, Discord can look a little complicated when getting started.
Helping A Friend Get Started: Midjourney (on YouTube)
AI Art Generators recognise some artists, not others. I’ve shown you a few. Apparently Victo Ngai’s name works really well. But it doesn’t recognise one of my favourites: Dahlov Ipcar.
Personally, I’m happy to play around with contemporary artists for viewing pleasure. But outside this post, if I’m generator art for something, I’d rather not invoke a specific artist’s name. Instead, I’d prefer to rely upon the much broader corpus, or else specific painters who’ve been dead for a century.
The Creativity of Text-based Generative Art, a paper by Jonas Oppenlaender
During my brief time using Midjourney, I noticed the intersecting societal prejudices which of course becomes part of AI algorithms. If I thought Midjourney was bad, Stable Diffusion is even worse:
This site let’s you search the giant database behind image-making AI systems like Stable Diffusion. It’s supposed to be for artists to see if their art is in the data, but it also shows the sheer volume of NSFW/toxic stuff that’s behind these AI tools. http://haveibeentrained.com
Arthur Holland Michel
In response to this tweet, Daniel Leufer said:
If you were wondering why so-called ‘general-purpose AI systems’ pose a risk to human rights in the very way they are designed and trained, here’s a good example Stable diffusion, the image generation model that is wowing the world, was trained on a database full of p0rn
While other image generation models, like Dall-E2 or Imagen, display the classic biases (i.e. nurse = woman, doctor = man), Stable Diffusion outdoes them in discrimination by miles because the main search result for ‘nurse’ is p0rnographic images of women in nurse outfits
We knew this would happen because of pioneering, and undoubtedly traumatic, research by folks like @Abebab into the datasets these things are trained on
Another note is that Stable Diffusion is a perfect example of why just being open source shouldn’t be a loophole to dodge obligations on these things. Stable Diffusion arguably has more impact precisely because it’s fully open and available
Not saying it’s easy to regulate these things, or that we should keep such systems closed, but we are being confronted by really difficult questions that have real-life, tangible, discriminatory impact on women & minoritised & racialised folks
@djleufer
