
UPDATE NOVEMBER 2022: There is now a one-click installer for Windows and Linux. No tech know-how required.
UPDATE END OF OCTOBER 2022: It is now officially impossible for me to keep up. I’ve installed Automatic1111 locally and am pretty much focused on that, now.
Deep Dream Generator is a great place to start. You get 70 credits which keep accumulating over time, regardless of when you use them. (So use it in the morning, at lunchtime and at night for way more than 70 credits per day.)
But! Here is a massive list of places to use Stable Diffusion in your browser over on Reddit.
And here is the top comment with how to use Stable Diffusion locally on your own computer. You need a powerful NVidia GPU to do that, though the requirements are getting lower month by month.
Stable Diffusion is a “text-to-image diffusion model”. You’ve probably heard the of DALL-E 2 AI art generator because of the amazing progress it made in 2022. Midjourney is a private company making use of various generator technology which runs on super powerful servers. I spent a month playing with Midjourney and wrote about that here.
Midjourney uses a secret-sauce mixture of DALLE-2 and other things. If you’ve tried Midjourney’s --test parameter, you’ve actually been using Stable Diffusion. Midjourney has a monthly fee which is cheap or expensive depending on how you look at it.
At the moment, you can only use fast, unlimited Stable Diffusion on your own computer for free if you have an NVidia graphics card with at least 6GB of RAM. (So it’s not truly free.)
If you don’t have a powerful graphics card but you do have a Google account, you can ‘rent’ (free of charge) Google’s GPUs for extended sessions.
TRY artEMai
Brand new, experimental. 26 Sept 2022: “Guest users are now limited to 1 request per 30 seconds.
This service is provided as is.
No support is currently offered.
We will be launching officially soon!
This is called Waifu Diffusion: a text-to-image model conditioned on high-quality anime images. But it runs stability.ai (Stable Diffusion v1.4) Only generates square images 512×512.
Just because it’s been trained for anime and manga art doesn’t mean it only does that. After a brief play around, it does seem to do linework very well compared to last month’s Midjourney, at least.

This is not what I was going for when asking for a real Lisa Simpson but the line work looks really clean for AI.
You do get rubbish drawings like this unless you put in the name of an artist, and even then you sometimes still do.
(People are making compilations of artists recognized by Stable Diffusion. It has already become gauche to use the name of Greg Rutkowski.)

Made with artEMAI: “High resolution hypermaximalist cinematic overdetailed saturated telephoto photo of a BLT sandwich, extremely detailed, hdr, food photography,molecular gastronomy”

Made with artEMAI: “half man half rat, portrait, detailed, unreal engine, realistic”

Made with artEMAI: “raining baked beans, flood of baked beans, cityscape, cinematic view, cinematic lighting, storm, establishing shot”

Made with artEMAI: “low frequency, suburban street at night”

Made with artEMAI: “cottage on a high hill, surrounded by soft trees, lakeside, rain and thunderstorm, hd, realism, realistic, highly detailed watercolor”
DREAMLIKE.ART
They’re in beta, so are not charging yet. The guy’s a bit overloaded because he’s using his own home computers.
STABLE HORDE
Stable Horde is a Free crowdsourced distributed cluster for Stable Diffusion
You can use a no-installation, no-gpu, os-agnostic client or the command-line, or just the REST API
There is a ratio system. The more your generate, the more priority you have for your own prompts.
The browser version is a demo, but it cannot save to hard-disk due to browser isolation. It also runs only on Chrome due to itch.io/Firefox incompatibilities.
No image to image yet.
USE GOOGLE’S HARDWARE
Google Colaboratory or “Colab” is a Google product that allows anyone to write and run Python code through the browser. Indeed, it’s basically a Jupyter notebook, but running on Google’s powerful servers instead of locally.
How to Run Stable Diffusion Without A Graphic Card (GPU) (Python In Office)
Another useful article at ByteXD, which has screenshots and a tutorial:
Stable Diffusion WebUI, which allows us to use Stable Diffusion, on our computer or via Google Colab1, using an intuitive web interface with many interesting and time saving options and features, allowing us to continuously experiment with creating AI generated images for free.
ByteXD
Why would Google offer this? Their business model includes offering free resources to researchers and practitioners for machine learning research. There are time usage limits. You get booted off after a while and have to set it up again.
STABLE DIFFUSION FOR CHEAP (NOT FREE)
There are online companies which allow you to rent computer power for low prices. At the moment, these websites are getting a real workout and you may find it a little difficult to secure what you need, but two options are: RunPod and vast.ai
Maybe you’ve got a Stable Diffusion fork up and running on your own PC or Mac. But if you need, say, 24GB of VRAM to train your own images (textual inversion) this is an affordable option (especially when compared to the price of graphics cards).
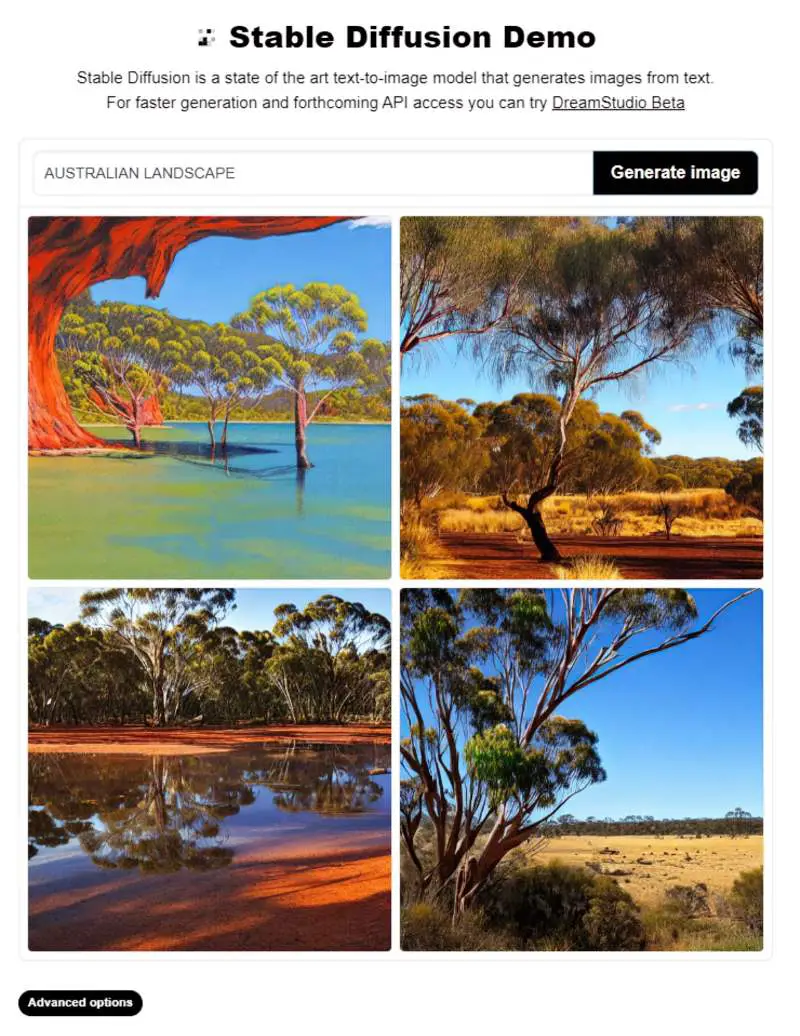
STABLE DIFFUSION DEMO (FREE ONLINE)
At the moment you’ll find the Hugging Face Stable Diffusion Demo frequently ‘too busy’ and you’ll get an error message. (It’s pretty slow.)
AS A PLUG-IN FOR YOUR ART SOFTWARE
As of this week, some plugins have been released too early and are unstable; others are about to be released.
KRITA STABLE DIFFUSION PLUGIN
(An option requiring technical know-how.)
Krita is a professional free and open source painting program. People have started to release Stable Diffusion plug-ins for it..
Not yet stable.
Installation instructions (on GitHub)
ADOBE PHOTOSHOP STABLE DIFFUSION PLUGIN
Stable Diffusion Photoshop Plugin by Christian Cantrell
CLIP STUDIO STABLE DIFFUSION PLUGIN
It’s called NekoDraw
BLENDER STABLE DIFFUSION PLUGIN
Stable Diffusion is great at making tileable textures, so of course that’s extremely useful in Blender.
FOR MAC OWNERS
DIFFUSION BEE
If you have an M1 or M2 Mac, Divam Gupta has made a new easy-to-use software called Diffusion Bee. Your Mac needs to run macOS 15.2 or newer.
1) Full data privacy – nothing is sent to the cloud
2) Clean and easy to use UI
3) One click installer
4) No dependencies needed
5) Multiple image sizes
6) Optimized for M1/M2 Chips
7) Runs locally on your computer
The interface looks really simple. You can’t really mess that up. If you have a Mac, that would be a great place to start making AI generated art with Stable Diffusion, though you might soon look for something with more options. It doesn’t come with an uninstaller so when you delete it, use an app cleaner.
CHARL-E
Also requiring an M1 or M2 Mac, CHARL-E packages Stable Diffusion into a simple app. No complex setup, dependencies, or internet required — just download and say what you want to see.
Everything runs locally. You don’t need Internet. You can provide weights with this one.
PRIVATE COMPANIES ONLINE
Since the release of Stable Diffusion, you don’t need to pay to create AI generated artwork.
If you would like to mess around with Stable Diffusion for a bit to see if you can be bothered with the faff of getting into the technical weeds, you can make use of the free credits offered by various companies online.
CANVA (SIMPLE DESIGN SOLUTIONS WITH SUBSCRIPTION OPTION)
Have a Canva account? Stable Diffusion is now available on free and paid accounts. Canva announced this on 15 September.
At time of writing, looks like you can only generate square images.
DREAM STUDIO (FREE CREDITS WITH PAY PER IMAGE AFTER THAT)
Stability.ai released Stable Diffusion to the public on August 22 2022. (They are behind the online demo above, and the entire release.)
Stability.ai is a network of developer communities who build AI tools, not just for images but also for language, audio, video, 3D and biology.

Before entering DreamStudio for the first time you’ll be asked to log in. (I used my Google account.) The software is currently in open beta, meaning anyone can join it but don’t expect perfection. Here’s the message you get:
DreamStudio is a front end and API to use the recently released stable diffusion image generation model.
It understands the relationships between words to create high quality images in seconds of anything you can imagine. Just type in a word prompt and hit “Dream”.
The model is best at one or two concepts as the first of its kind, particularly artistic or product photos, but feel free to experiment with your complementary credits. These correlate to compute directly and more may be purchased. You will be able to use the API features to drive your own applications in due course.
Adjusting the number of steps or resolution will use significantly more compute, so we recommend this only for experts.
The safety filter is activated by default as this model is still very raw and broadly trained. This may result in some outputs being blurred, please adjust the seed or rerun the prompt to receive normal output. This will be adjusted as we get more data. Please use this in an ethical, moral and legal manner. Make your mothers proud.
We hope you enjoy having a trillion images in your pocket, please do share and tag your output with #StableDiffusion!
DreamStudio open beta message
With DreamStudio you pay per generation. You get 200 credits for free.
They very recently moved to open beta and they may be having a few issues. I’ll only say this: Make sure you’re being charged what you should be charged.
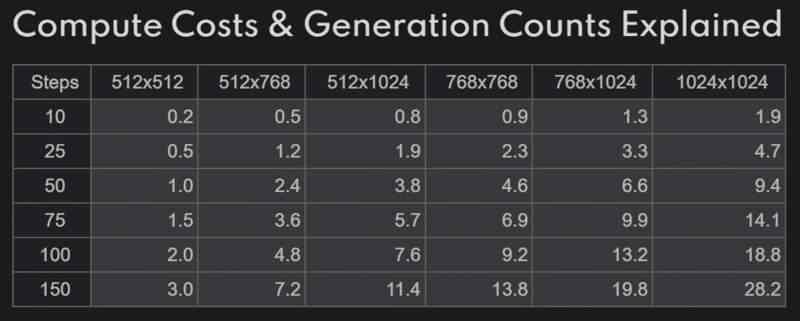
The cost of a DreamStudio generation isn’t immediately obvious when you create it, so can cost you a lot before you realise. However, they’ve tried to make it as easy-to-understand as possible:
1p for 1 credit which is 1 image at 512 x 512, 50 steps klms. Expect this to fall as we optimise this continuously.
announcement on their Discord
Tips and Tricks: How to save credits
Throw $10 into DreamStudio and then generate your test images at 10 steps with k_euler_ancestral. It’s really fast (batches of 9 are quick), and at 10 steps, you pay $0.002/image at 512×512. Every batch of 9 test images would cost you $0.018. Convert to your local currency if not American, but it’s very low: 5,000 images for a little over the American federal minimum wage for one hour.
someone on Reddit
HOW TO USE DREAMSTUDIO
Note: Storage of generations is local in your own browser. Generate a bunch and then download your favourite.
This is the DreamStudio control panel. If you’re a non-technical artist, this looks way more user friendly than all those GitHub documents but honestly, what does ‘k_lms’ mean? Generating AI art wtih DreamStudio is still crapping in the dark, but isn’t that part of the fun?
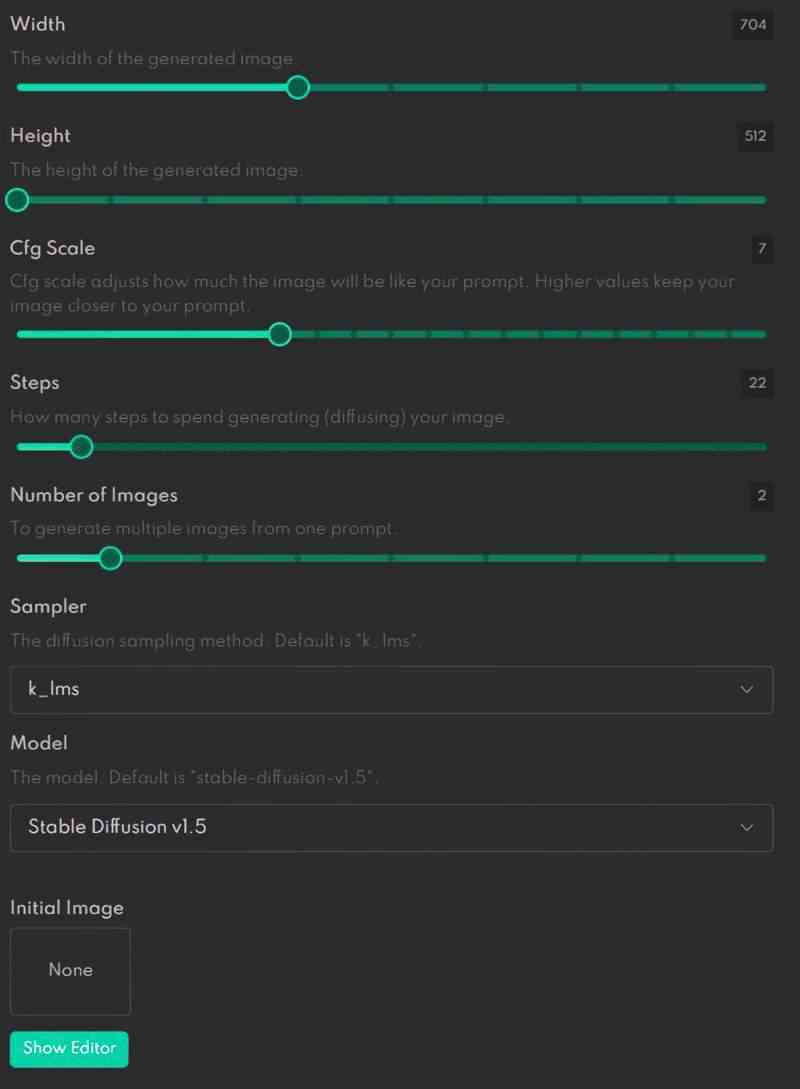
SIZE OF IMAGE
Width and height are obvious. The numbers refer to pixels. Unlike in Midjourney, there’s no native way to upscale images. You’ll need to use separate software for that. They give a list when you sign in. Another option is Topaz Photo AI which has just been released to replace their suite of separate software, but it’s fairly expensive.
CFG SCALE
CFG stands for “classifier free guidance” scale. How much free guidance do you want to give this AI artist of yours?
According to DreamStudio:
Cfg scale adjusts how much the image will be like your prompt. Higher values keep your image closer to your prompt.
Lower values produce more creative results. It also seems to affect the amount of detail.
Someone did an experiment from 0-100 and put it on Reddit using the prompt: “ansel adams photograph of an Mediterranean summer city by shaun tan and greg rutkowski and Dan McPharlin in the style of Ralph McQuarrie”
STEPS
How many steps to spend generating (diffusing) your image.
How bizarre do you want it to look? If you set it really low, you’ll get realism. Set it high, you’ll get fantasy, but also off-the-wall stuff. If you’re trying to art direct, set it low.
NUMBER OF IMAGES
To generate multiple images from one prompt.
SAMPLER
The diffusion sampling method. Default is “k_lms”.
The dropdown menu gives the following options:
- ddim
- plms
- k_euler
- k_euler_ancestral
- k_heun
- k_dpm_2
- k_dpm_2_ancestral
- k_lms
After testing all of these using the same settings, I don’t believe you need to bother adjusting these, at least not when starting out. For me they did the same job!
MODEL
Two options here: version 1.4 and 1.5. The default is 1.5, but if you’re having massive issues with it on any given day, try using the older version.
INITIAL IMAGE
Here you can upload a seed image from your own computer. You can also adjust image strength. By default it is set to 50%. You can only upload a single image as seed.
Midjourney lets you use more than one image Instead of uploading it from computer, you enter a url. However, Midjourney does not make direct use of your image. It goes back to its own database and gives you whatever it thinks you want.
If you want to use your image directly e.g. because you like the colours, or because you want to create AI art based on your own artwork, Midjourney won’t currently get you there. DreamStudio Lite is a much better tool. (I tried and tried to tell Midjourney which colours to use. It wasn’t listening.)
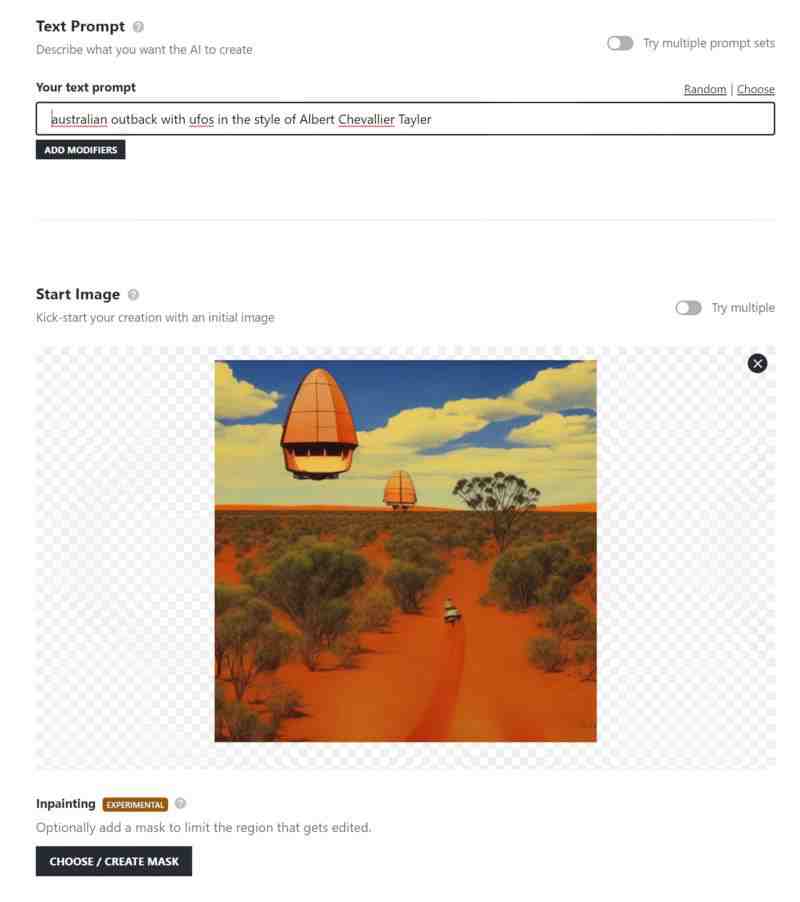
As an experiment, I used the following picture book cover as initial image because I love the colours and style. Also, I’ve been unable to reproduce the ‘retro picture book look’ using Midjourney AI.
I’m using the default sampler and the default model (k_lms, v1.5). I have left the Cfg Scale at 7, with 22 steps. (I guess these are defaults for a reason.)

When making use of seed images in Midjourney, users are advised to describe the image in the text prompts (thereby creating a double up). So I tried doing that first. If I ask for a train, will it give me a different train, but in this cool retro picture book style?
Conclusion: The sweet spot for borrowing colour and style of a painting seems to sit between 25-35%. Once you exceed 55% you’re only making minor alterations to the seed image.
Let’s try the same experiment, using the same seed image. Note, I’m only rollinig once. (I didn’t have to roll 100 times to get something good. Not even twice!)
This time I want a factory on the horizon of a rural landscape. I don’t want any train. I only want the line style and colour to transfer over.
Take a look! I think the sweet spot for this style and colour transfer experiment was 35%.
I went with image number 2 from 35% image weight. Here’s a closer look. It reminds me very much of American 20th century picture book illustrator Bill Peet. Honestly, you can’t do this with Midjourney. If I try ‘in the style of bill peet’ at Midjourney, his name is not recognised. And Midjourney has its own highly recognisable colour palette as well. It’s nice to get away from that.
So what happens if I take my favourite image with the same image seed, the same image weight and use one of those other engines from the ‘Sampler’ drop down menu? This is an imperfect experiment since you get a different image every time, even using the same sampler. But maybe the difference will be stark and obvious?
Conclusion: It was not stark and obvious. These are too small for you to see, but even close up, I see no difference between Samplers.
No matter which Sampler I chose, I got the same kind of thing: In a 4 image generation I got something that looked like watercolor, something approaching flat design, something that looks like Picasso making a picture book and something which retains those thick dark outlines.
I did run out of credits however, and if you play around with the settings more, you might see a difference.
NIGHT CAFE STUDIO (5 FREE CREDITS PER DAY)
NightCafe is an established Australian company who were quick to add Stable Diffusion’s text-to-image capability to their existing ‘Coherent’, ‘Artistic’ and ‘Style Transfer’ algorithms. (Meaning: They already had a text to image algorithm, which now looks pretty crap compared to 2022’s developments, and also an algorithm which transfers an artwork’s style onto a different image.)
They have a subscription model but if you visit their site daily they give you five free credits. (And they send you an email at the time you checked the box the previous day. Annoying but effective at pulling you back, I guess.) The good thing about NightCafe Studio: Once you run out of free credits, they drip-feed you more. The only catch is you have to keep going back to their site to redeem them.
For subscribers, 250 credits costs $20/per month. $80/month gets you 1500 credits. I’d expect that to get you unlimited. (Midjourney and DreamStudio start to look cheaper now, right?)
NightCafe advantages:
- It saves progress images, which means you can choose one with less detail if it looks better (and it frequently does, with AI generated art).
- They’ve just started trialling an inpainting tool, which lets you ‘evolve’ an artwork after painting over the parts of the image that you want the prompt to apply to. The rest of the image will be unaffected. The brush can change in size and you can zoom in and out while painting your mask (which isn’t a given at this point).
- It’s simple and intuitive to use multiple prompts. So if you have two or more cool paintings and you want to apply both styles to your AI generated artwork, NightCafe makes this easy.
- You get a pop up warning message if NightCafe thinks you might be about to waste some credits.
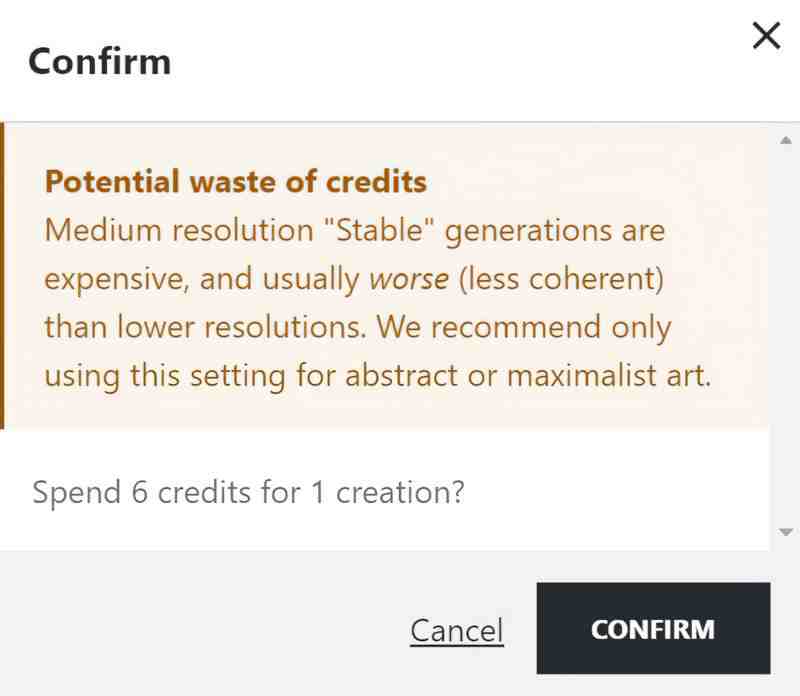

At NightCafe Studio, ‘ENHANCE’ means ‘upscale’ and ‘EVOLVE’ means ‘take one of the images just generated and use it as base for a new image. (Otherwise known as ‘img2img’.)
StarryAI (AN APP)
StarryAI also makes use of Stable Diffusion.
They have an app on the App Store and on Google Play. Like NightCafe, you get 5 free credits per day. Also like NightCafe, they give you a few more for sharing your generated artworks (promoting for them). The free versions will show you a lot of ads. You can purchase credit packs.
It has been widely agreed that DreamStudio returns better results, but all of these apps continue to get better and better. It’s difficult to keep up with which one is ‘best’. Ultimately, the best version is the app you have learnt how to use.
ArtBreeder (FREE, MONTHLY FEE FOR PRO)
The new Artbreeder Beta is powered by Stable Diffusion. It’s free with limitations.
Starts at $8.99 per month for fast image creation, Google Drive sync, privacy controls and other features.
This company allows you to create characters in different styles of art e.g. manga, realistic oil painting etc. You blend and alter using sliders until you get the character you want.
BoroCG reviews art software on YouTube and made a video about this, too. He found that merging characters gets better results than messing around with sliders when creating characters. They call it ‘crossbreeding’.
RUNNING STABLE DIFFUSION ON A PC (REQUIRES SOME TECH KNOW-HOW)
- Download Stable Diffusion from GitHub.
- Run it on your own computer using Python interpreter and command line.
Others have written detailed guides. We used this one to install Automatic1111. (It’s pronounced Automatic Eleven Eleven. Picked at random, frankly. Without testing them all out I don’t know the difference.) We are running this on a NVidia 3060 graphics card with 12 GB of RAM. AI image generation is faster than the ‘fast’ option I was getting with a Midjourney subscription last month.
When I say “we” set this up, I handed this off to the resident tech person.
“How good were those instructions?” I asked, after it was up and running.
“I ran into a problem with one of the steps.”
“How did you fix it? I’m hoping to blog about this for non-technical artist types like me.”
“Ah, it was way too technical to get into. And also I’ve forgotten what I did. I’d have to do the whole thing again.”
“Could a technically minded high school student do it?”
“Mm. Not sure.”
If, like me, you do not have a basic knowledge of Git and Miniconda3 installation, you will probably find it frustrating.
In case you’re wanting to pay someone, or to ring in a favour: How many hours did it take our resident tech guru to set up? (He has 30 years background working in IT, working in both software and hardware.)
Well, it was mostly a matter of waiting around for huge files to download. It took all Sunday to download the files. (About 4GB, I think?) and it required a bit of babysitting. Once something finishes downloading, you have to start the next thing. Downloads kicked off at about 10am. Stable Diffusion was up and running by midnight. Results will vary, but you can use that information when negotiating a pay rate.
And how much help will the IT person need to give the non-techy user after setting it up? I have it set up on my own PC via remote desktop. I had to be shown how to log into that. A bunch of things needed to be typed into console. “But this only needs doing once.”
Honestly, if I didn’t have an IT knowledgeable person living in the same house, I might just pay for DreamStudio. It all depends on how much you plan to use this thing. You could wait a couple months and easier options will likely become available open source.
I’m talking to artists here, and also perhaps to teachers who would like to offer students the opportunity to investigate the powers of AI art without waiting. If one of your classroom computers has a really good NVidia graphics card, perhaps the school’s IT person will set it up for you?
So far I’m having great fun playing with Automatic1111 on my own PC for free. I’ll let you know what the settings do as soon as I’ve figured them out.
I can already see advantages to installing this locally, aside from the fact it is free:
- You can create tiles to make repeating patterns simply by checking a box.
- It has a built-in image upsizer! Yay! Paid versions cost quite a bit!
- You don’t have to worry about ridiculously banned words.

The downside so far is that it’s not showing me progress images, so how would I know when to ‘interrupt’?
Here’s a screenshot of Automatic1111 for you. Although this thing required technical expertise to set up, this free Stable Diffusion interface I’m seeing on my screen is clean and appealing, like any of the paid versions. (Now if only I those nice-looking buttons could work…)
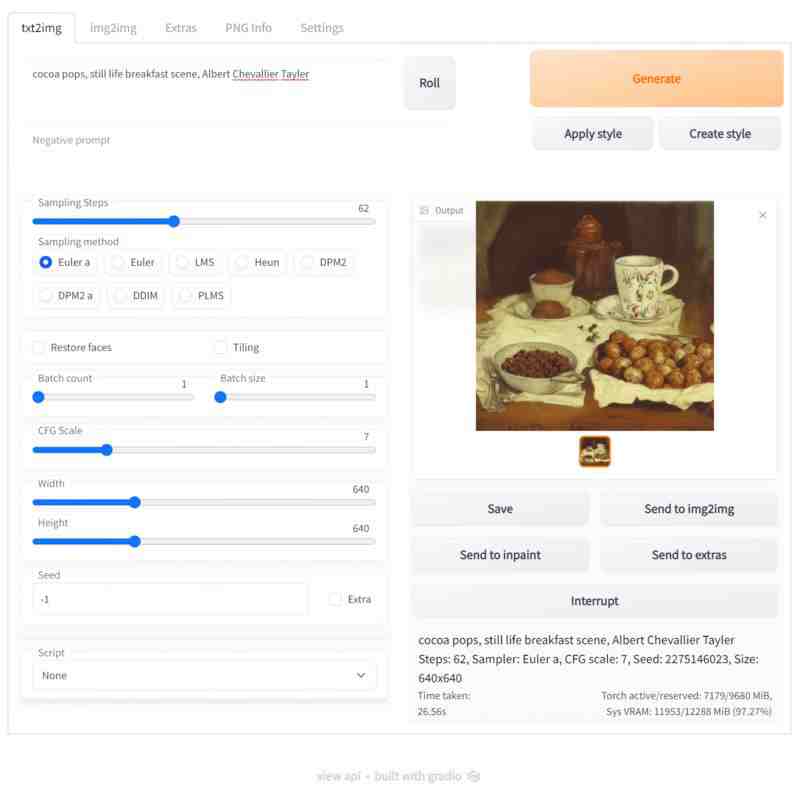
I can’t comment on how Automatic1111 compares to the other libraries.
FREE STABLE DIFFUSION RESOURCES
Browse objects and styles taught by the community and use them in your prompts
- Prompt Examples and Experiments at Strikingloo
- The Lexica Stable Diffusion Search Engine Has a reverse image search. Upload a photo and it’ll return the most similar Stable Diffusion images and their prompts. This means users can easily turn a real world concept into a Stable Diffusion prompt, and is useful for generating concepts which might be hard to describe in words.
- Hugging Face Concepts Library
OTHER
Choosing colour is an important step for an artist since colour conveys tone, atmosphere, branding etc but if you’re starting from scratch and are at the brainstorming stage, London based artist Matt Desluariers made an AI tool to generate colour palettes from any text prompt. (He put the code on GitHub.)

